











Configuration de Screaming Frog
Une bonne configuration de votre outil sera très importante pour pouvoir analyser en profondeur un site et obtenir toutes les données dont vous avez besoin. Découvrez pas à pas comment le configurer pour en tirer le meilleur parti.
Lancer votre premier crawl Screaming frog :
En arrivant sur l’outil, la première chose que vous pourrez voir est une barre dans laquelle vous pourrez entrer l’URL du site que vous souhaitez analyser :

il vous suffit donc de renseigner votre url et de sélectionner start pour lancer votre premier Crawl. Une fois lancé, si vous souhaitez l’arrêter il vous suffira de cliquer sur Pause puis Clear pour remettre à 0 votre crawl.
Configurez votre Screaming Frog SEO Spider :
Il existe de nombreuses possibilités pour configurer votre crawler afin qu’il ne remonte que les informations qui vous intéressent réellement. Cela peut être très utile par exemple lorsque vous crawlez des sites avec énormément de pages ou souhaitez analyser simplement un sous domaine.
Pour cela rendez vous dans le menu supérieur et sélectionnez Configuration
1/ Spider
CRAWL
Spider est la première option qui est disponible lorsque vous entrez dans le menu de configuration. C’est ici que vous pourrez décider les ressources que vous souhaitez crawler
Vous devriez normalement avoir une fenêtre qui se présente ainsi :
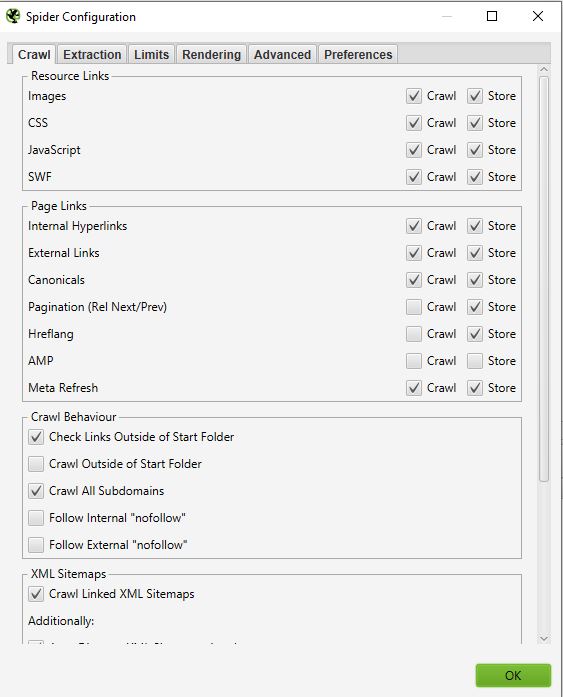
- Ressources links :
Vous pouvez par exemple décider de ne pas crawler les images du site, Screaming frog excluera ainsi de son crawl tous les éléments img : (img src=”image.jpg”). Votre crawl sera ainsi plus rapide mais vous ne pourrez pas mener d’analyse sur le poids des images, les attributs alts des images…
A vous de choisir à partir de cela ce que vous avez besoin d’analyser.
Bon à savoir : Il peut néanmoins arriver que vous ayez quelques images qui remontent si elles sont sous forme de a href et n’ont pas de img src
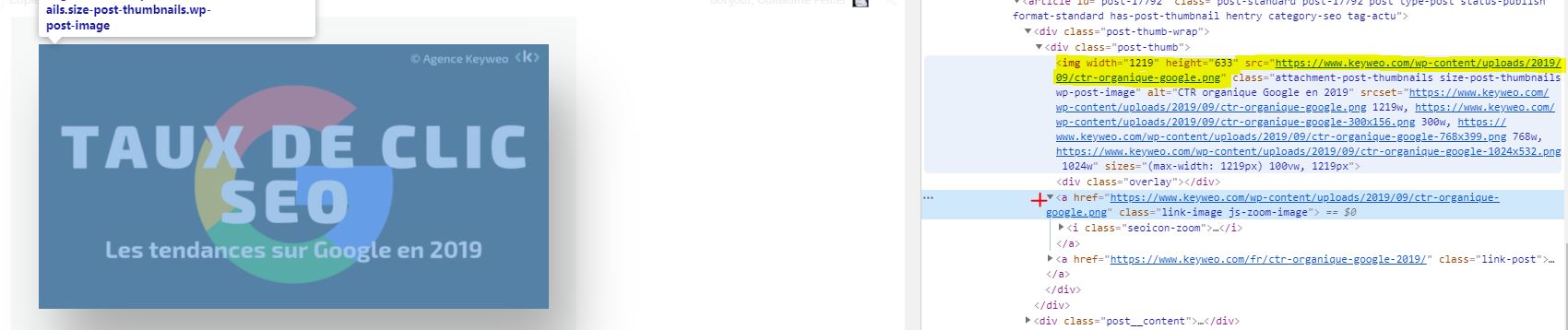
Dans le screenshot ci dessus, ce qui est en jaune ne sera pas crawlé par contre le lien de l’image avec la croix rouge sera tout de même crawlé
Sur la majorité de vos crawls vous aurez une configuration assez basique dans cette fenêtre. Nous vous recommandons de cocher le crawl et le storage des images, du css, du javascript et des fichiers SWF pour une analyse en profondeur.
- Page links :
Dans cette partie on peut décider également ce qu’on souhaite crawler en termes de liens. Vous pouvez par exemple dire que vous ne souhaitez pas crawler les canonicals ou les liens externes. Encore une fois, ici c’est à vous de choisir ce que vous souhaitez analyser.
Exemple :
Crawl avec external links et sans external links
Crawl avec external links :
Crawl sans external links :
- Crawl Behaviour
Dans cette partie vous pouvez donner des instructions à l’outil pour qu’il aille crawler certaines pages spécifiques de votre site.
Exemple :
Vous avez des pages en sous domaine et souhaitez tout de même les crawler pour les analyser. En cochant Crawl All subdomains, Screaming Frog s’il y a un lien vers ces pages sur votre site pourra vous les remonter dans son crawler.
Ci dessous vous pouvez voir un site qui dispose d’un sous domaine de type : blog.nomdedomaine. En sélectionnant crawl all subdomains avant de lancer notre Crawl, l’application nous fait ressortir également toutes les urls de ce sous domaine.

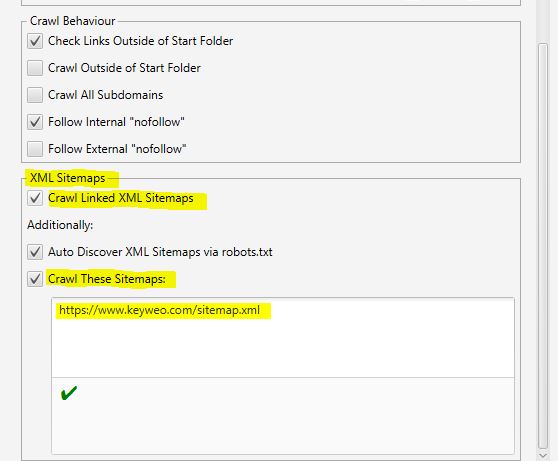
- XML Sitemaps
Vous avez un Sitemap sur votre site ? Il pourrait être intéressant alors d’analyser les ecarts entre ce que vous avez dans votre Sitemap et les urls que Screaming Frog trouve.
C’est dans cette partie que vous pouvez dire à Screaming Frog ou est votre Sitemap afin qu’il puisse l’analyser.
Pour cela il vous suffit de :
1- Cocher Crawl Linked XML Sitemaps
2- Cocher Crawl these sitemaps
3- Renseigner l’url de votre sitemap
EXTRACTION
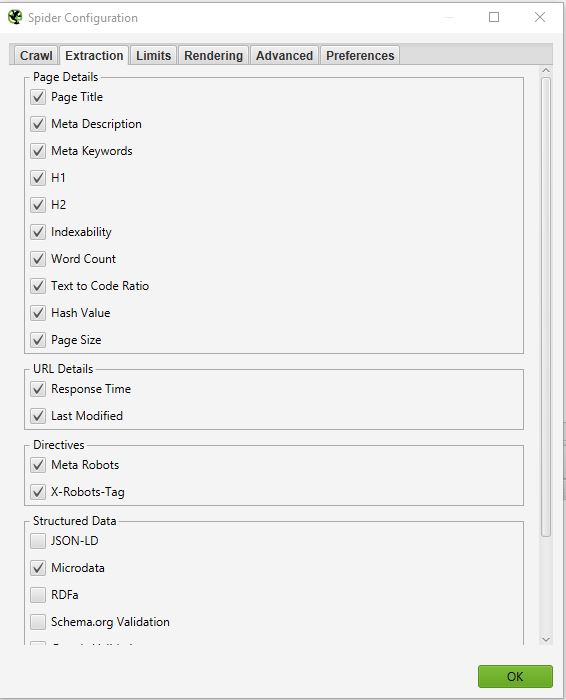
Dans cette partie vous pourrez choisir quelles données vous souhaitez que Screaming Frog puisse extraire de votre site et remonter dans son interface.
Exemple :
Si vous décochez Word Count, vous n’aurez plus le nombre de mots de chacune de vos pages crawlées
Normalement vous ne devriez pas trop modifier cette partie car en général les informations extraites de votre site qui sont sélectionnées par défaut sont les principales.
Une chose parfois qui peut être intéressante si vous souhaitez faire un audit SEO en profondeur c’est de sélectionner les informations liées aux Structured data : JSON-LD, Microdata, RDFa, Schema.org Validation.
Vous pourrez ainsi remonter de précieuses informations sur l’implémentation des micro datas sur votre site telles que : les pages qui n’ont pas de microdatas, les erreurs associées, les types de micro datas par page
LIMITS
Dans ce troisième onglet il est possible de définir des limites pour le crawler. Cela peut être particulièrement utile lorsque l’on souhaite analyser des sites avec beaucoup de pages.
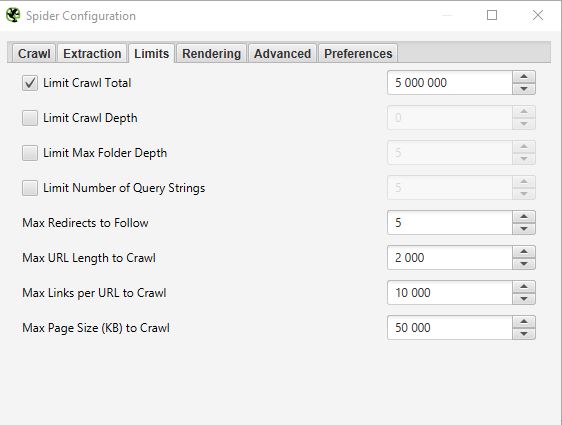
- Limit Crawl total :
Cela correspond au nombre d’urls que screaming peut crawler. En général lorsque nous analysons un site ça ne fait pas forcément sens de limiter à un nombre d’urls. C’est pourquoi en général nous ne touchons pas à ce paramètre
- Limit Crawl Depth :
Cela correspond à la profondeur maximale à laquelle vous souhaitez que le crawler puisse accéder. Le niveau 1 étant les pages situées à un clic de la homepage et ainsi de suite. Nous ne modifions presque jamais ce paramètre car il est intéressant de regarder justement dans un audit SEO la profondeur maximale d’un site. Dans le cas où elle serait trop importante il faudra mener des actions associées pour la réduire.
- Limit Max Folder Depth :
Dans ce cas, c’est la profondeur maximale de dossier à laquelle vous souhaitez que le crawler puisse avoir accès
- Limit number query string :
Certains sites peuvent avoir dans leurs urls des paramètres de type ?x=… . Cette option va vous permettre de limiter le crawl aux urls contenant un certain nombre de paramètres.
Exemple : Cette url https://www.popcarte.com/cartes-flash/carte-invitation/invitation-anniversaire-journal.html?age=50&format=4 contient deux paramètres age= et format= . Il pourrait être intéressant de limiter le crawl à un seul paramètre pour éviter de crawler des dizaines de milliers d’urls.
Cette option est elle aussi très utile pour des sites de e commerce avec de nombreuses pages et des listings avec des liens croisés.
- Max redirect to Follow :
Cette option permet de définir le nombre de redirects que l’on souhaite que notre crawler puisse suivre
- Max URL Length to Crawl :
Vous pourrez en modifiant ce champs sélectionner la longueur des urls que vous souhaitez crawler. De notre coté nous ne l’utilisons presque jamais hors cas très spécifique
- Max links per URL to Crawl :
Vous pouvez ici contrôler le nombre de liens par url que le Screaming Frog va pouvoir crawler
- Max page Size to Crawl :
Vous pouvez ici choisir le poids maximum des pages que votre crawler va pouvoir analyser
RENDERING
Cette fenêtre sera particulièrement utile si vous souhaitez par exemple crawler un site fonctionnant avec un framework javascript comme Angular, React, etc
Si vous analysez un site de ce type vous pouvez configurer votre crawler de cette façon :
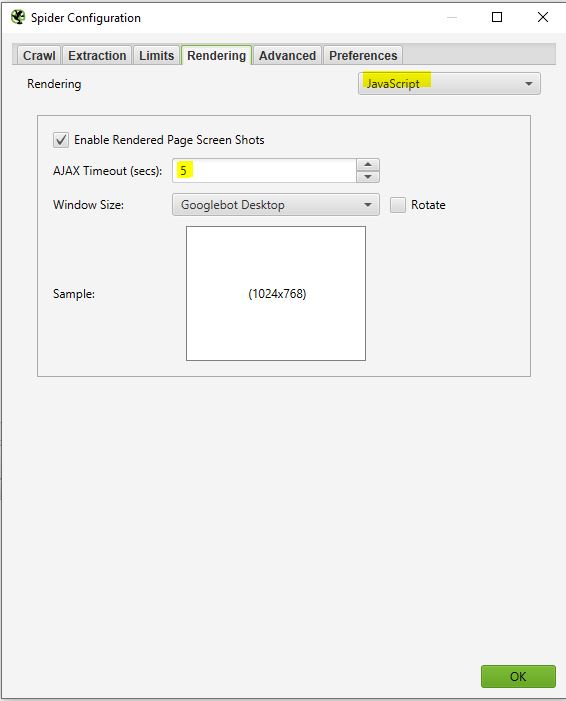
Screaming frog prendra des screenshots des pages crawlées que vous pourrez retrouver ensuite dans votre résultat de crawl en cliquant sur les urls qui remontent et en sélectionnant rendered page.
Si vous voyez que le rendu de votre page n’est pas optimal dans cette partie, regardez les ressources bloquées dans le cadre de gauche et vous pouvez essayer de modifier le AJAX TIMEOUT.
ADVANCED
Si vous êtes arrivés jusque la c’est que vous avez déjà une belle configuration de votre crawler. Néanmoins si vous souhaitez aller encore plus loin vous pouvez encore gérer certains paramètres dans cette partie « Advanced ».
Voici quelques configurations qui pourraient être utiles :
- Pause on High memory usage :
Cette option est pré cochée par défaut dans votre panneau de configuration de screaming frog. Elle sera notamment très utile et pourra se déclencher lorsque vous crawlez des sites de taille importante. En effet Screaming frog lorsqu’il arrivera a la limite de sa mémoire pourra mettre en pause le processus de crawl et vous prévenir pour que vous puissiez sauvegarder votre projet et le poursuivre si vous souhaitez.
- Always follow redirect :
Cette option est utile dans le cas ou vous auriez des chaines de redirection sur le site que vous êtes en train d’analyser.
- Respect noindex, canonical et next-prev:
Le crawler dans ce cas ne vous affichera pas dans les résultats de votre crawl les pages qui contiennent ces balises. Cela peut encore une fois être intéressant dans le cas ou vous analysez un site avec beaucoup de pages
- Extract images from img srcset attribute :
Le crawler dans ce cas va extraire les images avec cet attribut. Cet attribut est principalement utilisé dans des cas de gestion responsive d’un site. A vous de voir s’il est pertinent de récupérer ces images
- Response Timeout (secs) :
C’est le temps maximum que devra attendre le crawler pour qu’une page se charge sur le site. Si ce temps est dépassé Screaming frog pourra renvoyer un code 0 correspondant à un « connection timeout »
- 5xx response retries :
Cela correspond au nombre de fois que screaming frog doit retester une page en cas d’erreur 500
PREFERENCES
Dans cette partie vous allez pouvoir réellement définir ce que Screaming frog doit remonter en erreur.
Vous pourrez par exemple définir le poids maximal des images à partir duquel on peut considérer ça comme un problème ou encore la taille maximum d’une méta description ou d’une balise title.
Ici c’est à vous de définir vos règles SEO en fonction de votre expérience et de vos envies.
2/ Robots.txt
Félicitation d’être arrivé jusque la. La première partie n’était pas évidente mais sera vitale pour une bonne configuration de votre crawler. Cette partie sera beaucoup plus simple que la précédente.
En sélectionnant Robots.txt dans le menu vous pourrez configurer comment Screaming frog doit interagir avec votre fichier robots.
SETTINGS :
Vous devriez normalement voir ceci en arrivant dans la partie Robots settings
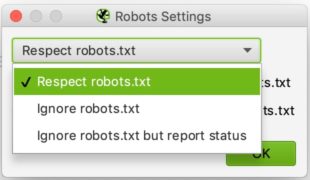
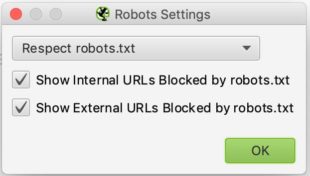
La configuration ici est relativement simple. Dans la liste déroulante vous pouvez dire à Screaming frog s’il doit respecter ou non les indications du fichier robots.txt.
Le cas du ignore robots.txt pourrait par exemple être utile si le site que vous souhaitez analyser ne permet pas à Screaming de le crawler pour quelques raisons que ce soit. En sélectionnant ignore robots.txt, Screaming Frog ne l’interprétera pas et vous pourrez normalement crawler le site en question
Le cas du respect robots.txt est le cas qui est le plus récurrent et on peut dire ensuite avec les deux cases à cocher en dessous si l’on souhaite voir dans les rapports les urls bloquées par le robots.txt qu’elles soient internes ou externes.
CUSTOM :
Dans ce panneau de configuration vous pourrez simuler vous même votre robots.txt. Cela peut être particulièrement utile si vous souhaitez tester des modifications et voir les impacts lors d’un crawl.
A noter que ces tests n’impacteront pas votre fichier robots.txt qui est en ligne. Si vous souhaitez le modifier il faudra le faire vous même après avoir fait vos tests dans screaming frog par exemple
Voici un exemple de test :
Nous avons ajouté une ligne pour empêcher le crawl de toute url contenant /blog/
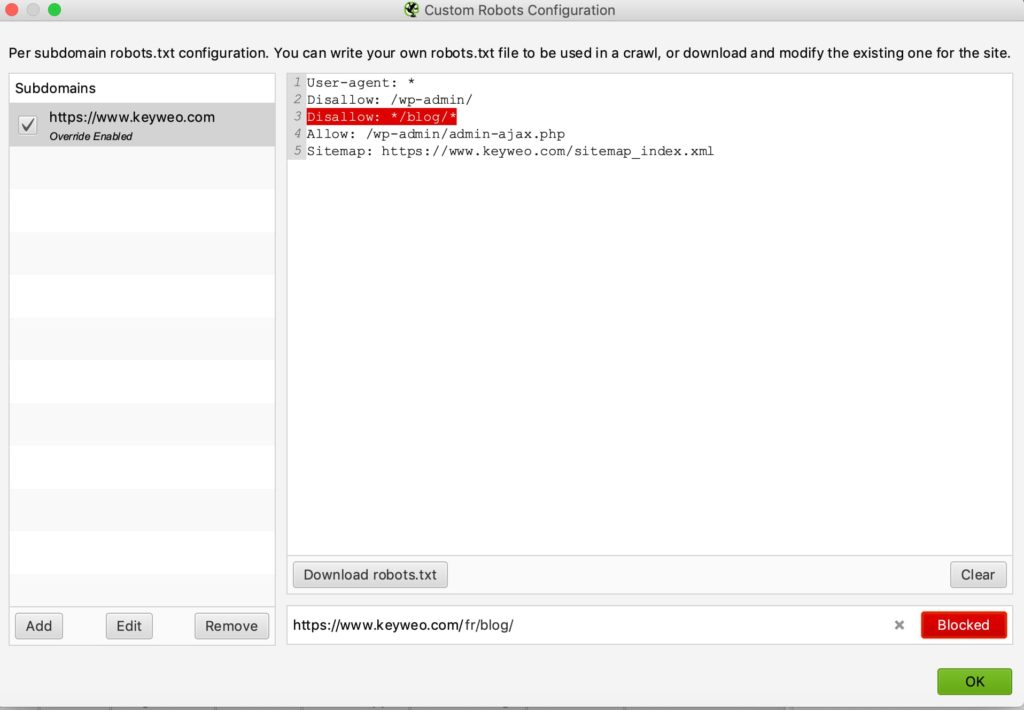
Si vous regardez en bas vous verrez que lors du test que nous avons réalisé avec keyweo.com/fr/blog l’url a bien été bloquée.
3/ URL Rewriting
Cette fonctionnalité sera très utile dans le cas ou vos urls contiennent des paramètres. Dans le cas par exemple d’un site de e-commerce avec un listing avec des filtres. Vous pourrez dans cette partie demander à Screaming Frog de réécrire les urls en vol.
REMOVE PARAMETERS
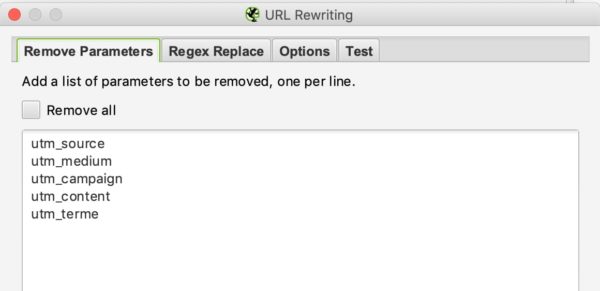
Vous pourrez dire au crawler dans cette partie de retirer certains paramètres pour ne pas en tenir compte. Cela pourrait être notamment très utile pour des sites avec des UTMs dans leurs urls
Exemple :
Si nous souhaitons retirer les paramètres utm dans nos urls vous pouvez mettre cette configuration :
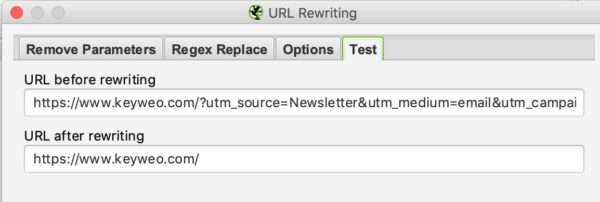
Puis pour tester si cela fonctionne il vous suffira de passer dans l’onglet test et mettre une url qui contient ces paramètres pour voir ce que cela donne :
REGEX REPLACE
Dans cet onglet vous pourrez remplacer des paramètres à la volée par d’autres. Vous pourrez trouver de nombreux exemples dans la documentation de screaming frog ici
4/ Include et Exclude
Chez Keyweo nous utilisons beaucoup ces fonctionnalités. C’est particulièrement utile pour des sites avec beaucoup d’urls si vous ne souhaitez crawler que certaines parties du site. Screaming frog pourra ainsi via les indications que vous faites dans ces fenêtres ne faire apparaitre que certaines pages dans sa liste de résultats du crawl.
Si vous gérez ou analysez des sites de grande taille cette fonctionnalité sera très importante à maîtriser pour vous économiser de nombreuses heures de crawl.
L’interface du include et exclude se présente de la manière suivante :
Vous pourrez lister les urls ou patterns d’urls à inclure ou exclure dans le cadre blanc en mettant une url par ligne.
Par exemple si je souhaite ne crawler sur Keyweo que les urls /fr/ voici ce que je peux mettre dans ma fenêtre include :
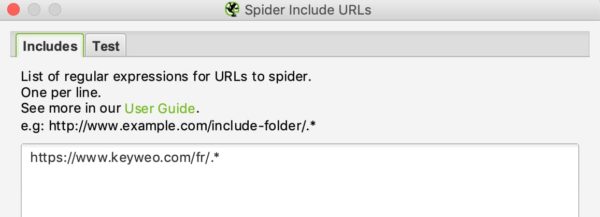
Vous pourrez comme pour l’url rewriting voir si votre include fonctionne en testant une url qui ne devrait pas être intégrée dans le crawl :
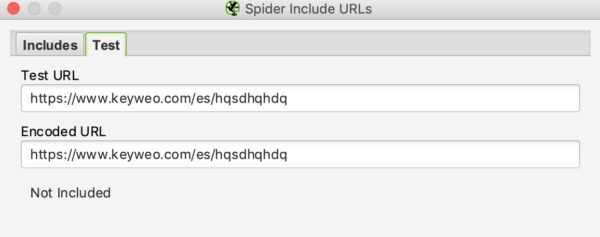
Dans notre exemple ci dessus on peut voir que l’include fonctionne puisque les urls contenant /es/ ne sont pas prises en compte.
Dans le cas ou vous souhaitez exclure certaines urls, la démarche sera similaire.
5/ Speed
Dans cette partie vous pouvez choisir à quelle vitesse vous souhaitez que Screaming Frog crawle le site que vous souhaitez analyser. Ca peut être utile quand vous souhaitez encore une fois analyser des sites de grandes tailles. En laissant la configuration par défaut cela pourrait mettre beaucoup de temps pour parcourir ce site web. En augmentant le Max Threads screaming frog pourra parcourir le site beaucoup plus vite.
Cette configuration est à utiliser avec précaution car cela peut augmenter le nombre de requêtes HTTP réalisées à un site ce qui pourrait le ralentir. Dans des cas extrêmes cela peut aussi faire crasher le serveur ou vous pourriez être bloqué par le serveur.
En général nous vous recommandons de laisser cette configuration entre 2 et 5 de Max Threads.
A noter également que vous pouvez définir un nombre d’urls à crawler par seconde.
N’hésitez pas à vous rapprocher des équipes techniques qui gèrent le site pour gérer au mieux le crawl du site et éviter une surcharge.
6/ User agent configuration
Dans cette partie vous pouvez définir avec quel user agent vous souhaitez crawler le site web. Par défaut ça sera Screaming frog mais vous pouvez par exemple crawler le site en tant que Google Bot (Desktop) ou Bing Bot
Cela pourrait être utile par exemple dans le cas ou vous n’arrivez pas à crawler le site car éventuellement le site bloque les crawls avec screaming frog.
7/ Custom Search and Extraction
CUSTOM SEARCH
Si vous souhaitez faire des analyses spécifiques en faisant ressortir des pages contenant certains éléments dans leur code HTML, vous allez aimer le Custom Search.
Exemples d’usage :
Vous souhaitez faire ressortir toutes les pages contenant votre code UA- Google analytics. Il pourrait être malin de faire une recherche via screaming en mettant votre code UA dans la fenêtre de la recherche. Cela pourrait par exemple vous servir à voir si certaines de vos pages n’ont pas le code analytics d’installé.
Vous êtes un blog sur la thématique naissance et souhaitez voir sur quelles pages apparaît le mot « box bébé » pour ensuite optimiser les pages qui le contienne ou l’inverse celles qui ne le contienne pas afin de mieux vous positionner sur cette requête. Il vous suffira donc de mettre dans votre fenêtre de custom search contain : « box bébé »
Vous verrez ainsi dans votre custom search de screaming frog ceci :
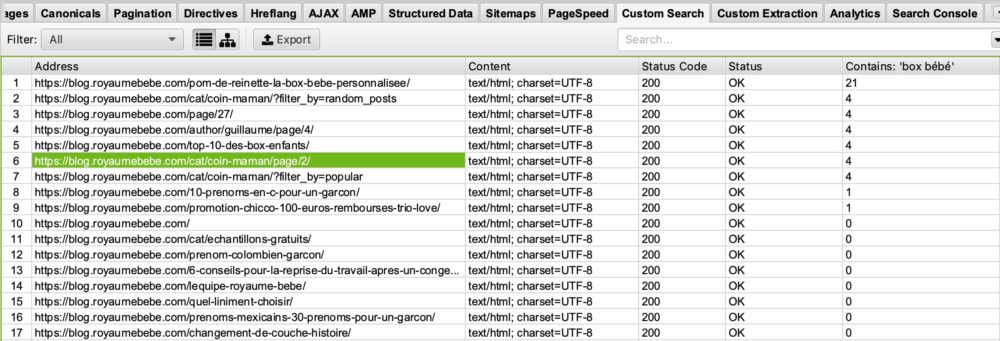
Si vous regardez dans la colonne « Contains Box Bébé » vous pourrez voir que screaming frog nous a listé les pages contenant box bébé. Je vous laisse imaginer à quoi ça peut vous servir par la suite dans vos optimisations SEO 🙂
EXTRACTION
Screaming frog via sa fonctionnalité Extraction peut également vous permettre de scraper certaines données pour les utiliser dans vos analyses plus poussées. Nous utilisons par exemple de plus en plus cet outil à l’agence pour certaines analyses spécifiques
Pour scrapper ces données il vous suffira de configurer votre extractor en lui indiquant ce qu’il doit récupérer via un Xpath, un CSSpath ou une regex.
Vous trouverez toutes les informations pour cette configuration via cet article : https://www.screamingfrog.co.uk/web-scraping/
Exemples d’usages :
Vous souhaitez récupérer la date de parution d’un article pour ensuite décider de nettoyer ou réoptimiser certaines articles. Cette fonctionnalité vous permettra de récupérer ces informations dans votre liste de résultats screaming frog et ensuite par exemple de les exporter sous excel. Super non ?
Vous souhaitez exporter la liste des produits de votre concurrents qui sont sur leurs pages de listing et qui sont dans des h2. Une fois de plus vous pourrez configurer simplement votre extracteur pour récupérer ces informations et ensuite vous amuser avec ces données sur Excel.
Les possibilités d’usage de cette fonctionnalité d’extraction sont vraiment illimités. A vous d’être créatif et de savoir la maîtriser parfaitement.
8/ API Access
C’est dans cette fenêtre que vous pouvez configurer la remontée des données depuis d’autres outils en configurant vos accès API. Vous pourrez par exemple remonter très simplement vos données google analytics, google search console, majestic SEO ou encore ahrefs dans vos tableaux avec les informations pour chaque urls. Autant vous dire que ça va démultiplier la puissance de vos analyses et audit.
Seul petit bémol, attention à regarder vos crédits API sur vos différents outils. Ca peut partir très vite.
9/ Authentication
Certains sites demandent un login et mot de passe pour pouvoir accéder à l’ensemble du contenu. Screaming Frog vous permet de gérer les différents cas d’accès via mot de passe et identifiant.
CAS BASIQUE D’AUTHENTIFICATION
Pour la majorité des cas vous n’aurez rien à configurer puisque par défaut si screaming frog rencontre une fenêtre d’authentification il vous demandera un identifiant et mot de passe pour pouvoir effectuer le crawl.
Voici la fenêtre que vous devriez avoir :
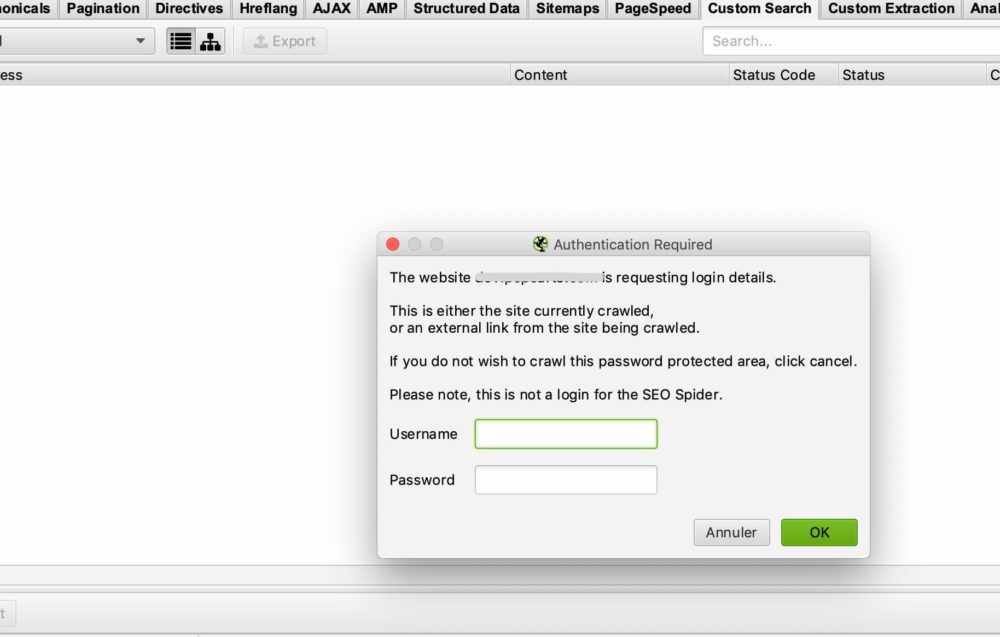
Il vous suffira donc de renseigner simplement le username et mot de passe et screaming frog pourra effectuer son crawl.
Dans certains cas il y aura peut être un blocage via le robots.txt. Il vous faudra alors vous reporter au point 2/ que nous avons vu pour ignorer le fichier robots.txt
CAS D’UN FORMULAIRE INTERNE AU SITE
Dans le cas d’un formulaire interne au site vous pourrez très simplement renseigner vos accès dans la partie authentication > form based pour ensuite permettre au crawler d’accéder aux pages que vous souhaitez analyser.
10/ System :
STORAGE
Cette fonctionnalité est également importante à maîtriser dans le cas ou vous devez crawler des sites avec plus de 500 000 URLS.
Vous avez dans cette fenêtre deux options : Memory storage and database Storage
Par défaut Screaming Frog utilisera le Memory storage ce qui revient à utiliser la RAM de votre ordinateur pour faire le crawl du site. Cela fonctionne très bien pour les sites qui ne sont pas trop gros. Néanmoins vous arriverez vite aux limites pour les sites au delà de 500 000 urls. Votre machine pourra être pas mal ralentie et le crawl durer relativement longtemps. Croyez en notre expérience.
Dans l’autre cas nous vous recommandons de passer en database Storage surtout si vous avez un disque SSD. L’autre avantage du database storage est que vos crawl pourront être sauvegardés et facilement retrouvés à partir de votre interface screaming frog. Même en cas d’arrêt du crawl vous pourrez le reprendre. Ça peut vraiment vous sauver dans certains cas de longues heures de crawl.
MEMORY
C’est dans cette partie que vous définirez la mémoire que peut utiliser screaming frog pour fonctionner. Plus vous augmenterez la mémoire plus screaming frog sera capable de crawler un nombre important d’urls. Surtout dans le cas ou il est configuré en Memory storage.
10/ Le mode de crawl :
SPIDER
Ce mode est la configuration basique de screaming frog. Une fois rentré votre URL, screaming frog va suivre les liens de votre site pour le parcourir entièrement.
LIST MODE
Ce mode est vraiment très pratique car il vous permet de dire à screaming frog de parcourir une liste d’urls précise.
Par exemple si vous souhaitez vérifier le statut d’une liste d’urls dont vous disposez, il vous suffira d’uploader un fichier ou de copier coller votre list d’urls manuellement.
SERP MODE
Ce mode ne fait pas intervenir de crawl. Il vous permet d’uploader un fichier avec par exemple vos titles et meta description pour voir ce que ça donnerait en termes d’optimisation SEO. Ca peut servir par exemple pour vérifier la longueur de vos titles et meta description après des modifications sur excel par exemple.
Analysez vos données issues du crawl
L’interface de screaming frog :
Avant de partir tête baissée dans l’analyse des données que vous présente screaming frog il est important de comprendre comment l’interface est structurée
Normalement vous devriez avoir quelque chose comme ça :
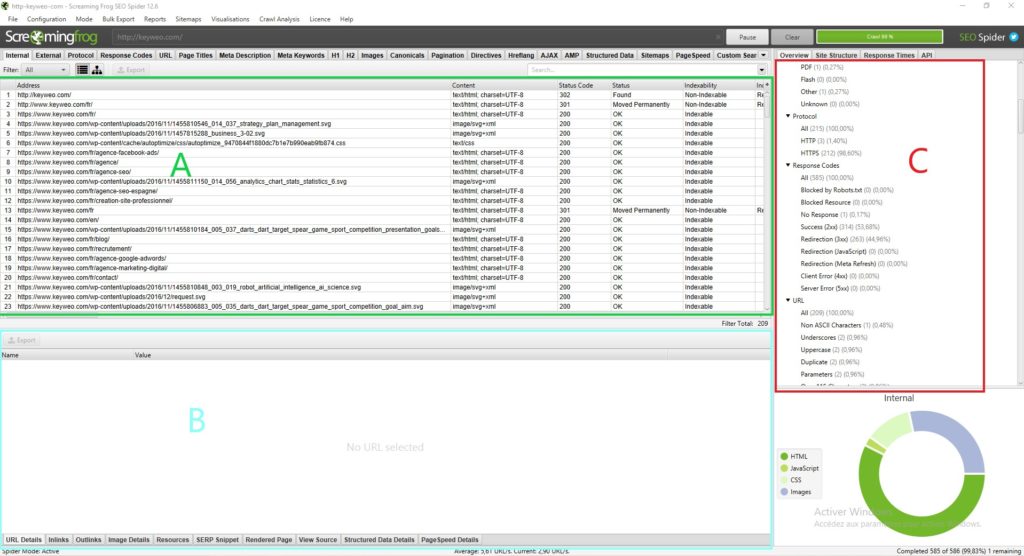
haque partie à une utilisation qui lui est propre et qui vous permettra de ne pas vous perdre dans les toutes les données disponibles :
Partie A (en vert) : Cette partie correspond à la liste des ressources crawlées avec pour chaque colonne des indications SEO qui sont propres à chaque ligne. En général c’est ici que vous retrouverez la liste de vos pages et les informations propres à chaque page comme le status code, l’indexabilité de la page, le nombre de mots… Cette vue changera en fonction de ce que vous sélectionnez dans la partie C.
Partie B (en bleu) : C’est dans cette partie que vous pourrez avoir une vision plus détaillée de chaque ressource que vous analysez en cliquant dessus. Par exemple vous pourrez avoir un aperçu pour une page de ses inlinks, des images présentes et de nombreuses autres informations qui pourront être très utiles.
Partie C (en rouge) : Cette partie sera importante à regarder pour mener vos analyses car c’est ici que vous pourrez voir point par point ce qui peut être optimisé et screaming frog vous donnera également quelques aides pour faciliter votre analyse. Exemple : Metadescription missing, H1 multiples…
Pour vous y retrouver dans l’analyse de vos données nous vous recommandons de vous déplacer via la partie C
L’overview (Partie C) :
1/ Le Summary :
Dans cette partie vous pourrez avoir une vision globale du site dont le nombre d’urls du site (images, html…), le nombre d’urls externes et internes bloquées par le robots.txt, le nombre d’urls que le crawler à pu trouver (internes et externes)
Vous aurez ainsi en un coup d’œil des informations précieuses sur le site.
2/ SEO Elements : Internal
Vous trouverez dans cette partie toutes les urls internes à votre site.
HTML
Il est généralement très intéressant de regarder le nombre d’urls HTML. Vous pourriez par exemple comparer votre nombre d’urls avec le nombre de pages indexées sur google avec la commande site: . Cela pourrait vous donner des informations très précieuses si de nombreuses pages ne sont pas indexées sur google par exemple.
En cliquant sur HTML vous verrez que votre partie de gauche contiendra de nombreuses informations très importantes à analyser telles que :
=> Status Code de la page
=> Indexabilité
=> Des informations sur les titles (Le contenu, la taille)
=> Des informations sur les meta description (Le contenu, la taille)
=> Meta Keyword : plus forcément très utile de le regarder hormis s’ils sont encore utilisé par le site en question. Vous pourriez par exemple cleaner ces balises
=> H1 (Le contenu, la taille, la présence d’un deuxième h1 et sa taille)
=> H2 (Le contenu, la taille, la présence d’un deuxième h2 et sa taille)
=> Meta Robots
=> X Robots Tag
=> Meta refresh
=> La présence d’une canonical
=> La présence d’une balise rel next ou rel prev
=> La taille de la page
=> Le nombre de mots de la page
=> Le text ratio : proportion entre texte et code
=> Crawl Depth : La profondeur de la page en question dans le site. La home etant en niveau 0 si vous commencez le crawl par cette page. Une page à 1 clic de la home sera en profondeur 1 et ainsi de suite. Sachant qu’il est généralement intéressant de réduire cette profondeur dans votre site
=> Inlinks / unique inlinks : nombre de liens internes pointant vers la page en question
=> Outlinks / Unique outlinks : nombre de liens sortants de cette page
=> Response time : temps de réponse de la page
=> Redirect URL : page vers laquelle est redirigée la page s’il y a une redirection
Vous pourrez également retrouver tous ces éléments en parcourant les différents éléments de la colonne de droite.
Si vous vous connectez aux api de la search console, google analytics, ahrefs… vous aurez également d’autres colonnes disponibles qu’il serait très intéressant d’analyser.
JAVASCRIPT, IMAGES, CSS, PDF…
En cliquant sur chaque partie vous pourrez avoir des informations intéressantes sur chaque type de ressources de votre site.
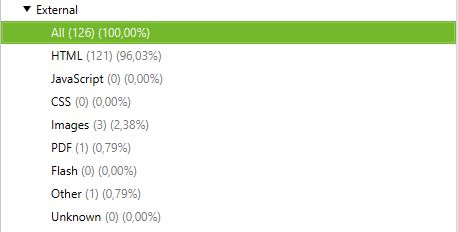
3/ SEO Elements : External
La partie external correspond à toutes les urls dirigeant en dehors de votre site. Par exemple c’est ici que vous pourrez retrouver tous les liens externes que vous faites.
Il pourrait par exemple être intéressant d’analyser les urls sortantes de votre site et regarder leur statut. Si vous avez des 404, il pourrait être judicieux de corriger votre lien ou de le supprimer pour éviter de renvoyer vers des pages cassées.
4/ Protocole :
Dans cette partie vous pourrez identifier les Urls HTTP et HTTPS.
Si vous avez beaucoup d’urls HTTP ou des pages en doublon en http et https il serait utile de gérer la redirection de vos pages HTTP vers leur version HTTPS
Autre point si vous avez des Urls en HTTP qui pointent vers d’autres sites vous pourriez vérifier si la version HTTPs de ces sites n’existe pas et remplacer les liens.
4/ Response Code :
La section Response Codes regroupe par type de code vos pages.
=> No response : Cela correspond en général aux pages que screaming frog n’a pas pu crawler
=> Success : Vous devriez avoir ici toutes vos pages en statut 200. C’est à dire qu’elles sont accessibles
=> Redirection : Vous devriez avoir dans cette partie toutes les pages en statut 300 (301, 302, 307…) . Il pourrait être intéressant de voir comment réduire ce nombre si possible pour envoyer directement google vers des pages en statut 200
=> Client Error : Vous aurez ici toutes les pages en erreur avec par exemple un statut 404. Il sera important de regarder la cause et faire une redirection.
=> Server Error : Toutes les pages remontant une erreur serveur
5/ URL :
Dans cette section retrouvez la liste de vos urls et les potentiels problèmes ou améliorations associées.
Vous pourrez par exemple voir vos urls avec des majuscules ou vos urls dupliquées
6/ Page Titles :
Vous aurez ici de nombreuses informations sur vos titles et pourrez les optimiser pour les rendre beaucoup plus SEO friendly.
Voici les informations que vous pourrez retrouver :
=> Missing : Cela correspondra à vos pages qui n’ont pas de title. Il faudra donc vous assurer de les ajouter si possible
=> Duplicate : Vous aurez ici tous les titles dupliqués de votre site. L’idéal étant d’éviter d’en avoir. A vous donc de voir comment les optimiser pour éviter cette duplication
=> Over 60 Characters : Au delà d’un certain nombre de caractères vos titles seront coupés dans les résultats de Google. Assurez vous donc qu’ils soient autour de 60 caractères pour éviter les problèmes
=> Below 30 Characters : Vous retrouverez ici les titles que vous pourriez optimiser en termes de taille. Rajoutez quelques mots stratégiques en vous rapprochant de 60 caractères pourrait vous permettre de les optimiser
=> Over 545 Pixels / Below 200 Pixels : Un peu comme les éléments précédents cela vous donne un indicateur de la longueur de vos titles mais cette fois en pixels. La différence étant que vous pourriez optimiser vos titles en utilisant des lettres avec plus ou moins de pixels pour maximiser l’espace.
=> Same as H1 : Cela veut dire que votre title est identique à votre h1
=> Multiple : Si vous avez des pages contenant plusieurs titles c’est ici que vous pourrez identifier ce problème et voir les pages à corriger
6/ Meta description :
Sur le même modèle que les titles vous aurez dans cette section de nombreuses indications pour optimiser vos meta description en fonction de leur taille, de leur présence ou du fait qu’elles soient dupliquées
7/ Meta Keywords :
Ce n’est pas forcément utile d’en tenir compte hormis si les pages semblent en avoir beaucoup pour les desoptimiser.
A vous de voir
8/ H1 / H2 :
Vous pourrez dans ces parties voir s’il y a des optimisations à mener sur vos balises Hn
Par exemple si vous avez plusieurs h1 dans une même page il pourrait éventuellement être intéressant de réfléchir à n’en garder qu’un si ça fait sens. Ou si vous avez des h1 dupliqués entre vos pages, vous pourriez faire en sorte de les retravailler
9/ Images :
Vous pouvez en analysant cette partie en général trouver des optimisations à mener sur vos images comme par exemple retravailler vos images de plus de 100kb ou mettre des alt sur les images qui n’en ont pas.
10/ Canonical :
Une canonical sert à indiquer à google qu’il doit aller voir telle ou telle page car c’est l’originale. Pour prendre un exemple vous avez une page avec des paramètres et cette page dispose d’un contenu dupliqué de votre page sans paramètres. Vous pourriez mettre une canonical sur la page avec paramètres pour indiquer à google que la page sans paramètre est la principale et qu’il doit plutot tenir compte de la page originale.
Dans cette partie de screaming frog vous aurez toutes les informations concernant la gestion des canonicals de votre site.
11/ Pagination :
Ici vous aurez toutes les informations concernant la pagination sur votre site afin que vous puissiez la gérer au mieux.
12/ Directives :
La partie Directives montre les informations contenus dans les méta robots tag et X-Robots-Tag. Vous pourrez notamment voir les pages en no index, les pages en no follow…
13/ Hreflang :
Lorsque vous auditez un site en plusieurs langues il est très important de regarder si le site dispose bien des balises hreflang pour aider google à comprendre quelle est la langue utilisée sur le site même si on peut supposer qu’il est de plus en plus capable de le comprendre lui même.
14/ AMP :
Vos pages AMP se retrouveront ici et vous pourrez identifier les problèmes SEO associés
15/ Structured data :
Pour avoir des informations dans cette partie vous devez dans un premier temps activer dans votre spider configuration les éléments propres aux structured data : JSON-LD, Microdata, RDFa
Vous aurez ensuite de nombreuses informations pour optimiser votre implémentation des données structurées sur le site.
16/ Sitemaps :
Vous pourrez dans cette partie voir les différences entre ce que vous avez sur votre site et dans votre Sitemap.
Par exemple c’est un bon moyen pour identifier vos pages orphelines.
Pour avoir des données dans cette partie vous devez également activer la possibilité de crawler votre Sitemap dans la configuration du crawler et pour simplifier la chose ajouter le lien vers votre Sitemap directement dans la configuration.
16/ Pagespeed :
En passant par l’API de page speed insight vous pourrez très simplement identifier les problèmes de vitesse de vos pages et y remédier en analysant les données présentes dans cet onglet
17/ Custom Search et Extraction :
Si vous souhaitez scraper des éléments ou faire des recherches spécifiques dans le code d’une page c’est ici que vous pourrez retrouver les données
18/ Analytics et Search Console :
En connectant également screaming frog aux api de Analytics et Search console vous pourrez retrouver de nombreuses informations très utiles dans ces onglets.
Par exemple vous retrouverez aussi ici les pages orphelines présentes dans vos outils mais pas dans le crawl ou encore les pages avec un taux de rebond supérieur à 70%
19/ Link Metrics :
Connectez Screaming Frog aux apis Ahrefs et Majestic et faites ressortir dans cette partie des informations à propos du netlinking de vos pages (exemple : Trustflow, citation flow…)
Les fonctionnalités additionnelles de Screaming Frog
Analyser la profondeur d’un site :
Si vous souhaitez voir la profondeur de votre site il peut être très intéressant de regarder dans l’onglet Site structure dans la partie de droite à coté de Overview :
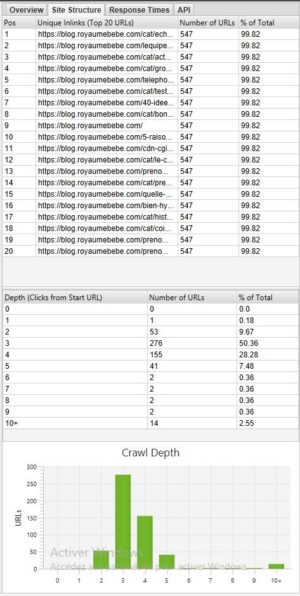
En général il est préférable d’avoir un site avec la majorité des pages accessibles en 3 – 4 clics. Dans notre exemple ci dessus par exemple il faudrait optimiser la profondeur car il y a des pages en profondeur 10+
Vision spatiale de votre site :
Une fois votre crawl fini il est parfois intéressant d’aller dans Visualisations > Forced directed crawl diagram pour avoir une vision d’ensemble de votre site sous forme de nœud
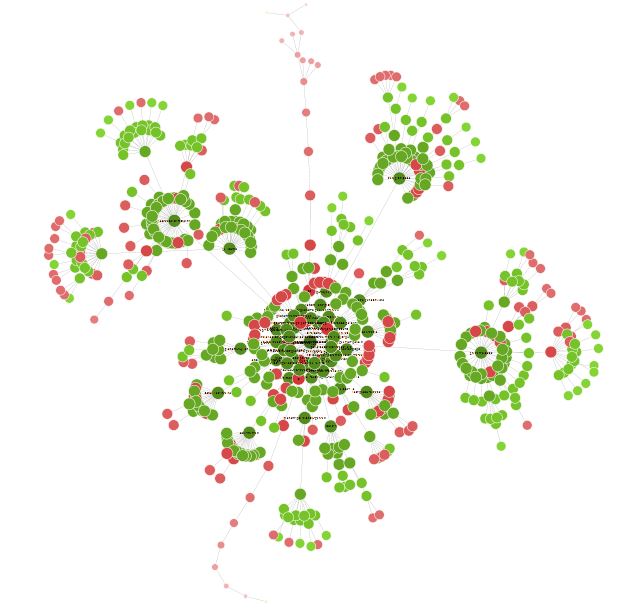
Tous les petits points rouges par exemple peuvent être analysés pour comprendre s’il y a un problème ou non.
Cette vision peut également vous amener à réfléchir sur l’organisation de votre site et son maillage interne.
Vous pouvez en passant un peu de temps avec cette visualisation trouver de nombreuses pistes d’optimisations très intéressantes.
Conclusion Screaming Frog
Screaming sera donc un outil indispensable à tout bon SEO. L’outil si vous le maitrisez en profondeur vous permettra de faire de nombreuses choses allant de l’analyse SEO technique au scraping de sites.