











Screaming Frog Konfiguration
Eine gute Konfiguration Ihres Tools ist sehr wichtig, um eine Website gründlich zu analysieren und alle Daten zu erhalten, die Sie benötigen. Finden Sie heraus, wie man es Schritt für Schritt konfiguriert.
Starten Sie Ihren ersten Crawl mit Screaming Frog:
Wenn Sie das Tool aufrufen, sehen Sie als erstes eine Leiste, in die Sie die URL der zu analysierenden Website eingeben können:

Geben Sie einfach Ihre URL ein und wählen Sie Start, um Ihren ersten Crawl zu starten. Wenn der Crawl gestartet ist und Sie ihn beenden möchten, klicken Sie einfach auf Pause und dann auf Löschen, um den Crawl zurückzusetzen.
Konfigurieren Sie Ihren ersten Crawl mit Screaming Frog:
Es gibt viele Möglichkeiten, Ihren Crawler so zu konfigurieren, dass er nur die Informationen liefert, an denen Sie interessiert sind. Dies kann sehr nützlich sein, wenn Sie Websites mit vielen Seiten crawlen oder wenn Sie eine Subdomain analysieren möchten.
Gehen Sie dazu in das obere Menü und wählen Sie Konfiguration:
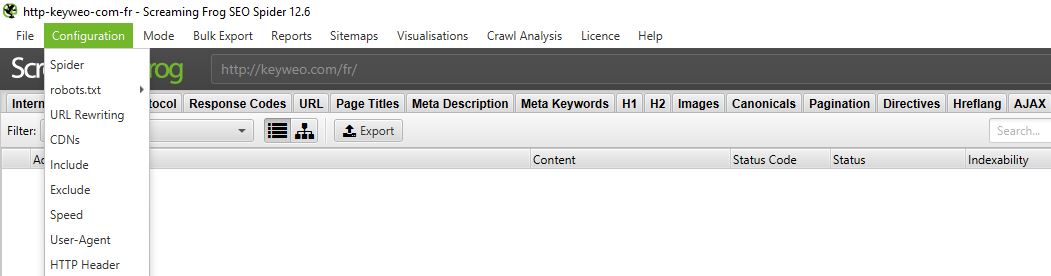
1/ Spider:
CRAWL
Spider ist die erste Option, die verfügbar ist, wenn Sie das Konfigurationsmenü aufrufen. Hier können Sie entscheiden, welche Ressourcen Sie crawlen möchten
Normalerweise sollten Sie ein Fenster erhalten, das wie folgt aussieht:
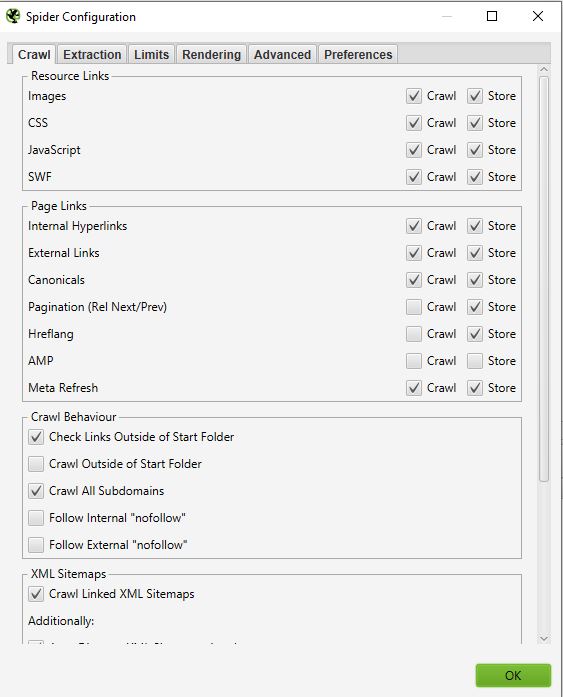
- Ressourcen-Links :
Sie können beispielsweise entscheiden, die Bilder der Website nicht zu crawlen. Screaming Frog wird alle Elemente mit IMG: (IMG src=”image.jpg”) ausschließen. Ihr Crawl wird schneller sein, aber Sie werden nicht in der Lage sein, das Gewicht der Bilder, die Attribute der Bilder usw. zu analysieren.
Es liegt an Ihnen, zu entscheiden, was Sie analysieren möchten.
Gut zu wissen: Es kann trotzdem vorkommen, dass einige Bilder hochkommen, wenn sie als a href vorliegen und keine img src besitzen.
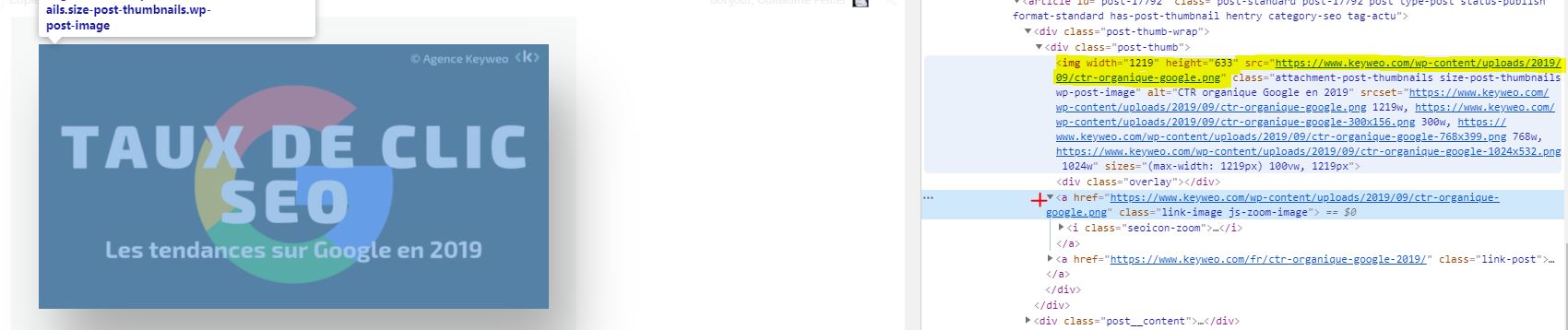
Im obigen Screenshot wird die gelbe Seite nicht gecrawlt, während der Link des Bildes mit dem roten Kreuz gecrawlt wird.
Bei den meisten Ihrer Crawls werden Sie in diesem Fenster eine sehr grundlegende Konfiguration vornehmen. Wir empfehlen Ihnen, das Crawlen und Speichern von Bildern, CSS-, Javascript- und SWF-Dateien für eine tiefgreifende Analyse auszuwählen.
- Seitenlinks:
In diesem Teil können Sie auch entscheiden, was Sie in Bezug auf Links crawlen wollen. Sie können zum Beispiel angeben, dass Sie keine kanonischen oder externen Links crawlen wollen. Auch hier bleibt es Ihnen überlassen, was Sie analysieren wollen.
Beispiel:
Crawl mit externen Links und ohne externe Links:
Crawl ohne externe Links:
- Crawl-Verhalten
In diesem Teil können Sie dem Tool Anweisungen geben, bestimmte Seiten Ihrer Website zu crawlen.
Beispiel:
Sie haben Seiten in einer Subdomain und wollen sie alle auf die gleiche Weise crawlen, um sie zu analysieren? Indem Sie “Crawl All Subdomains” aktivieren, kann Screaming Frog sie in seinen Crawler aufnehmen.
Unten sehen Sie eine Website mit einer Subdomain des Typs: blog. domain name. Indem wir “Crawl All Subdomains” auswählen, bevor wir unseren Crawl starten, zeigt die Anwendung alle URLs dieser Subdomain an.

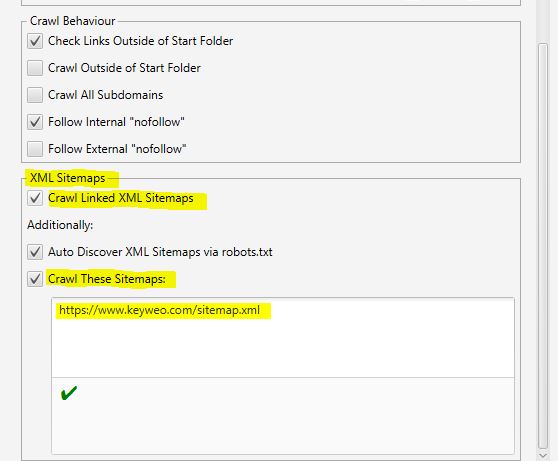
- XML-Sitemaps
Haben Sie eine Sitemap auf Ihrer Website? Dann könnte es interessant sein, die Lücken zwischen dem, was Sie in Ihrer Sitemap haben und den URLs, die Screaming Frog findet, zu analysieren.
Hier können Sie Screaming Frog mitteilen, wo sich Ihre Sitemap befindet, so dass es sie analysieren kann.
Hierfür müssen Sie nur folgendes tun:
1- “Crawl Linked XML Sitemaps” ankreuzen
2- “Crawl These Sitemaps” ankreuzen
3- Die URL Ihrer Sitemap eingeben
EXTRACTION
In diesem Teil können Sie auswählen, welche Daten Screaming Frog von Ihrer Website extrahieren und in seiner Schnittstelle anzeigen soll.
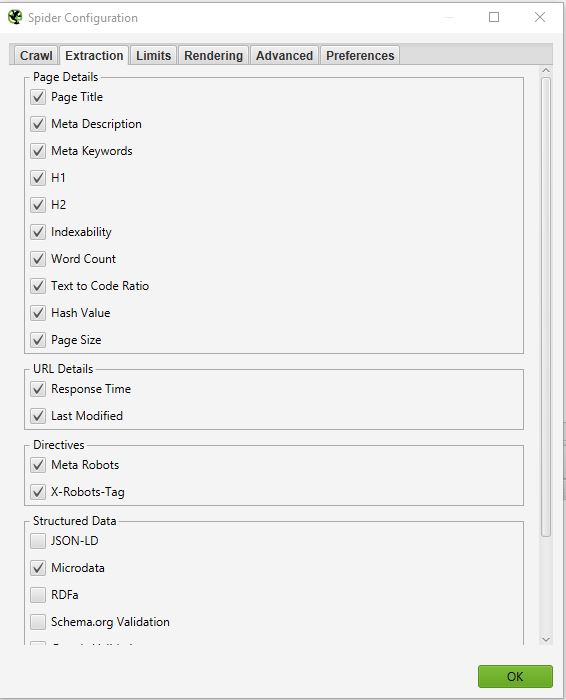
Beispiel:
Wenn Sie das Häkchen bei ” Word Count ” entfernen, werden Sie nicht mehr die Anzahl der Wörter auf jeder Ihrer gecrawlten Seiten sehen.
Wenn Sie eine eingehende SEO-Prüfung durchführen wollen, kann eine Sache interessant sein. Das ist die Auswahl der Informationen, die sich auf strukturierte Daten beziehen: JSON-LD, Microdata, RDFa, Schema.org Validation. Sie werden wertvolle Informationen über die Implementierung von Mikrodaten auf Ihrer Website erhalten.
LIMITS
In dieser dritten Registerkarte können Sie Grenzen für den Crawler festlegen. Dies kann besonders nützlich sein, wenn Sie Websites mit vielen Seiten analysieren möchten.
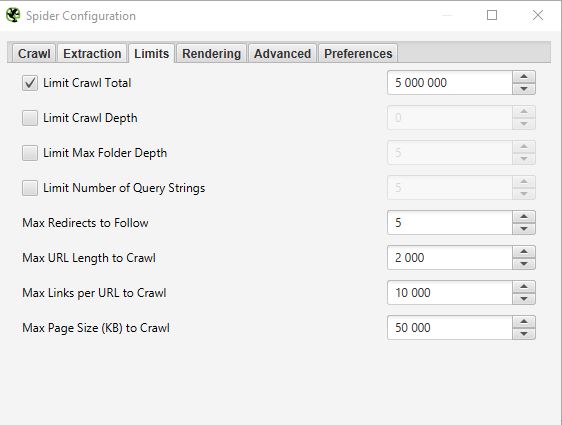
- Limit Crawl Total :
Dies entspricht der Anzahl der URLs, die Screaming Frog crawlen kann. Wenn wir eine Website analysieren, ist es im Allgemeinen nicht unbedingt sinnvoll, sie auf mehrere URLs zu beschränken. Deshalb lassen wir diesen Parameter im Allgemeinen unangetastet.
- Limit Crawl Depth :
Dies ist die maximale Tiefe, die der Crawler erreichen soll. Stufe 1 ist die Seite, die einen Klick von der Homepage entfernt ist, und so weiter. Wir ändern diesen Parameter nur selten, weil es interessant ist, die maximale Tiefe einer Website bei einem SEO-Audit zu betrachten. Wenn sie zu hoch ist, müssen wir Maßnahmen ergreifen, um sie zu verringern.
- Limit Max Folder Depth :
In diesem Fall handelt es sich um die maximale Ordnertiefe, auf die der Crawler Zugriff haben soll.
- Limit Number of Query Strings :
Einige Websites haben Parameter des Typs ?x= in ihren URLs. Mit dieser Option können Sie das Crawlen auf URLs beschränken, die eine bestimmte Anzahl von Parametern enthalten.
Beispiel: Die URL https://www.popcarte.com/cartes-flash/carte-invitation/invitation-anniversaire-journal.html?age=50&format=4 die beiden Parameter age= und format=. Es könnte interessant sein, das Crawlen auf einen Parameter zu beschränken, um zu vermeiden, dass Zehntausende von URLs gecrawlt werden.
Diese Option ist sehr nützlich für E-Commerce-Websites mit vielen Seiten und Verzeichnissen mit Querverweisen.
- Max Redirects to Follow :
Mit dieser Option können Sie die Anzahl der Weiterleitungen festlegen, denen Ihr Crawler folgen soll.
- Max URL Length to Crawl :
Durch Ändern dieses Feldes können Sie die Länge der URLs auswählen, die Sie crawlen möchten. Auf unserer Seite verwenden wir es selten, außer in sehr speziellen Fällen.
- Max Links per URL to Crawl :
Hier können Sie die Anzahl der Links pro URL festlegen, die der Screaming Frog crawlen soll.
- Max Page Size to Crawl :
Sie können das maximale Gewicht der Seiten wählen, die Ihr Crawler analysieren soll.
RENDERING
Dieses Fenster ist nützlich, wenn Sie eine Website crawlen wollen, die auf einem Javascript-Framework wie Angular, React, etc. betrieben wird.
Wenn Sie eine solche Website analysieren, können Sie Ihren Crawler wie folgt konfigurieren:
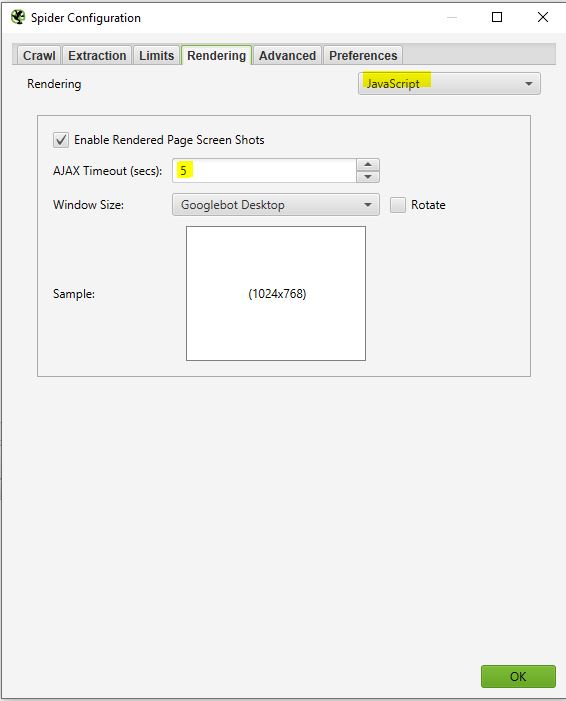
Screaming Frog macht Screenshots von den gecrawlten Seiten. Sie können diese in Ihrem Crawl-Ergebnis finden, indem Sie auf die angezeigten URLs klicken.
Wenn Sie sehen, dass Ihre Seite nicht optimal gerendert wird, sehen Sie sich die blockierten Ressourcen im linken Frame an und versuchen Sie, den AJAX TIMEOUT zu ändern.
ADVANCED
Wenn Sie diesen Punkt erreicht haben, bedeutet dies, dass Sie Ihren Crawler bereits sehr gut konfiguriert haben. Wenn Sie jedoch noch weiter gehen wollen, können Sie in diesem “Advanced”-Teil noch einige Parameter verwalten.
Hier sind einige Einstellungen, die nützlich sein könnten:
- Pause on High Memory Usage:
Wenn Screaming Frog an die Grenzen seines Speichers stößt, kann er den Crawling-Prozess unterbrechen und Sie darauf hinweisen, damit Sie Ihr Projekt speichern und fortsetzen können, falls Sie dies wünschen.
- Always Follow Redirects:
Diese Option ist nützlich, wenn Sie Weiterleitungsketten auf der zu analysierenden Website haben.
- Respect noindex, Canonical, Next/Prev:
Der Crawler wird Seiten, die diese Tags enthalten, nicht in den Crawl-Ergebnissen anzeigen.
- Extract Images from img srcset Attribute:
Der Crawler wird die Bilder mit diesem Attribut extrahieren. Dieses Attribut wird vor allem bei der responsiven Verwaltung einer Website verwendet. Es liegt an Ihnen zu entscheiden, ob es relevant ist, diese Bilder abzurufen.
- Response Timeout (secs):
Dies ist die maximale Zeit, die der Crawler warten muss, bis eine Seite auf der Website geladen ist. Wenn diese Zeit überschritten wird, kann Screaming Frog einen Code 0 zurückgeben, der einem “Verbindungs-Timeout” entspricht.
- 5xx Response Retries:
Dies ist die Anzahl, wie oft Screaming Frog eine Seite im Falle eines Fehlers 500 erneut aufrufen soll.
PREFERENCES
In diesem Abschnitt können Sie festlegen, was Screaming Frog als Fehler melden soll.
Sie können das maximale Gewicht der Bilder, der Meta-Beschreibung oder eines Titels festlegen, ab dem von einem Problem ausgegangen werden kann.
Hier liegt es an Ihnen, Ihre SEO-Strategie entsprechend Ihrer Erfahrung und Ihren Wünschen zu definieren.
2/ Robots.txt
Herzlichen Glückwunsch, dass Sie es bis hierher geschafft haben. Der erste Teil war nicht einfach, ist aber für eine gute Konfiguration Ihres Crawlers unerlässlich. Dieser Teil wird viel einfacher sein als der vorherige.
Indem Sie Robots.txt aus dem Menü auswählen, können Sie konfigurieren, wie Screaming Frog mit Ihrer Robots-Datei interagieren soll.
SETTINGS:
Dies sollten Sie sehen, wenn Sie zum Abschnitt Robotereinstellungen gelangen:
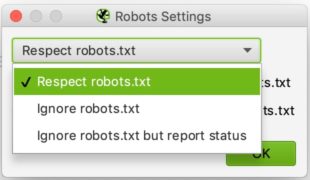
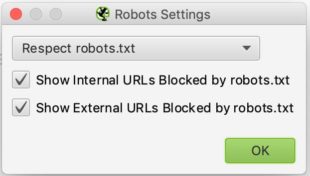
Die Konfiguration ist relativ einfach. In der Dropdown-Liste können Sie Screaming Frog mitteilen, ob es die Angaben der Robots.txt-Datei beachten soll oder nicht.
Das Ignorieren von robots.txt kann z.B. nützlich sein, wenn die Website, die Sie analysieren möchten, Screaming Frog aus irgendeinem Grund nicht erlaubt, zu crawlen. Indem Sie auswählen, robots.txt zu ignorieren, wird Screaming Frog sie nicht interpretieren und Sie können die fragliche Seite normal crawlen.
CUSTOM:
In diesem Bedienfeld können Sie Ihre Robots.txt selbst simulieren. Dies kann besonders nützlich sein, wenn Sie Änderungen testen und die Auswirkungen während eines Crawls sehen möchten.
Beachten Sie, dass sich diese Tests nicht auf Ihre Robots.txt-Datei auswirken. Wenn Sie sie ändern wollen, müssen Sie das selbst tun, nachdem Sie Ihre Tests in Screaming Frog durchgeführt haben.
Hier ist ein Beispiel für einen Test:
Wir haben eine Zeile hinzugefügt, um das Crawlen jeder URL zu verhindern, die /blog/ enthält.
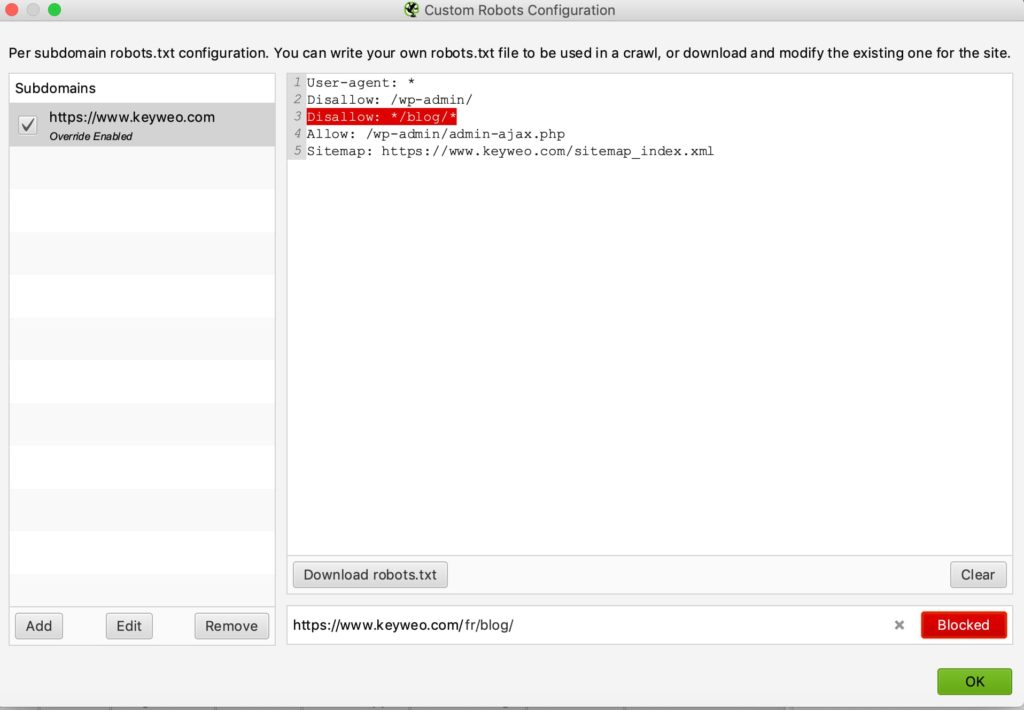
Wie Sie unten sehen, wurde bei dem Test, den wir mit keyweo.com/de/blog durchgeführt haben, die URL tatsächlich blockiert.
3/ URL Rewriting
Diese Funktion wird sehr nützlich sein, wenn Ihre URLs Parameter enthalten. Sie können Screaming Frog auffordern, die URLs umzuschreiben.
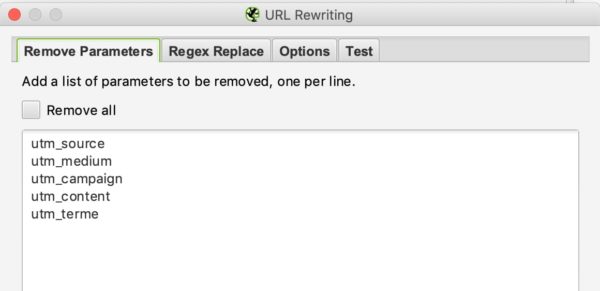
REMOVE PARAMETERS
Sie können den Crawler anweisen, einige Parameter zu entfernen, um sie zu ignorieren. Dies kann für Websites mit UTMs in ihren URLs nützlich sein.
Beispiel:
Unten sehen Sie ein Beispiel für einen Test, bei dem die URL von keyweo.com/en/blog blockiert wurde.
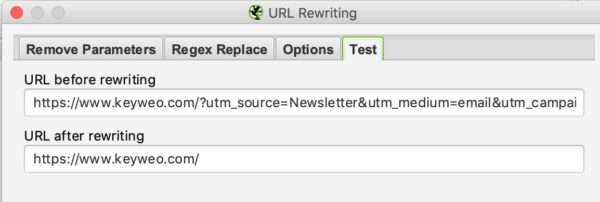
Um zu testen, ob es funktioniert, müssen Sie auf die Registerkarte “Test” gehen und eine URL eingeben, die diese Parameter enthält, um das Ergebnis zu sehen:
REGEX REPLACE
In dieser Registerkarte können Sie Parameter durch andere ersetzen. Finden Sie einige Beispiele hier.
4/ Include & Exclude
Bei Keyweo nutzen wir diese Funktionen sehr häufig. Sie sind besonders nützlich für Websites mit vielen URLs, und wenn Sie nur bestimmte Teile der Website crawlen wollen. Screaming Frog ist in der Lage, die von Ihnen gemachten Angaben zu nutzen, um nur bestimmte Seiten in seiner Liste der Crawl-Ergebnisse erscheinen zu lassen.
Wenn Sie große Websites verwalten oder analysieren, ist es sehr wichtig, diese Funktion zu beherrschen, da sie Ihnen viele Stunden an Crawling ersparen kann.
Die Schnittstelle von include und exclude sieht wie folgt aus:
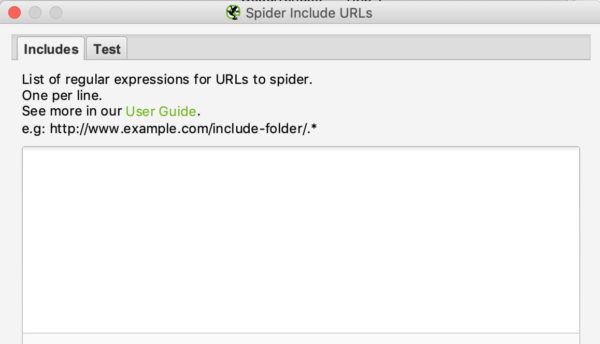
Sie können die URLs, die Sie ein- oder ausschließen möchten, auflisten, indem Sie eine URL pro Zeile in das weiße Feld eingeben.
Wenn ich zum Beispiel nur die /fr/ URLs von Keyweo crawlen möchte, kann ich folgendes in mein Include-Fenster eingeben:
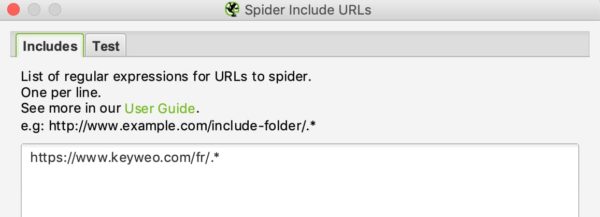
Sie können die URL auch in der Testbox testen. Wie beim URL-Rewriting können Sie sehen, ob Ihr Include funktioniert, indem Sie eine URL testen, die nicht in den Crawl aufgenommen werden sollte:
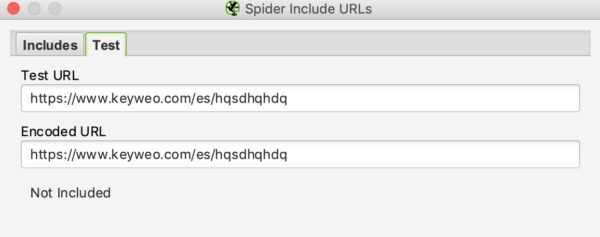
In unserem Beispiel oben können Sie sehen, dass der Include funktioniert, da URLs, die /es/ enthalten, nicht berücksichtigt werden.
Wenn Sie bestimmte URLs ausschließen möchten, ist die Vorgehensweise ähnlich.
5/ Speed
In diesem Teil können Sie wählen, wie schnell Screaming Frog die zu analysierende Seite crawlen soll. Dies kann nützlich sein, wenn Sie große Websites scannen wollen. Wenn Sie die Standardeinstellung beibehalten, kann es sehr lange dauern, diese Website zu crawlen. Wenn Sie die Max Threads erhöhen, wird Screaming Frog in der Lage sein, die Seite viel schneller zu crawlen.
Diese Konfiguration sollte mit Vorsicht verwendet werden, da sie die Anzahl der HTTP-Anfragen an eine Seite erhöhen kann, was die Seite verlangsamen kann. In extremen Fällen kann es auch zum Absturz des Servers führen oder dazu, dass Sie vom Server blockiert werden.
Im Allgemeinen empfehlen wir Ihnen, diese Konfiguration bei 2 bis 5 Max Threads zu belassen.
Sie können mehrere URLs festlegen, die pro Sekunde gecrawlt werden sollen.
Zögern Sie nicht, die technischen Teams zu kontaktieren, die die Website verwalten, um das Crawlen der Website zu optimieren und eine Überlastung zu vermeiden.
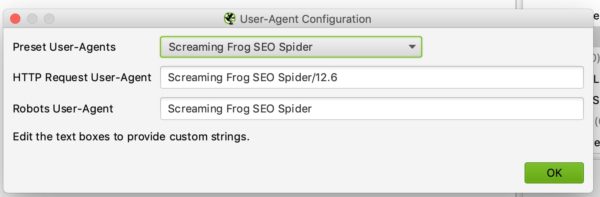
6/ User-Agent Configuration
In diesem Abschnitt können Sie festlegen, mit welchem User Agent Sie die Website crawlen möchten. Standardmäßig wird dies Screaming Frog sein, aber Sie können die Website zum Beispiel als Google Bot (Desktop) oder Bing Bot crawlen.
Dies kann zum Beispiel nützlich sein, wenn Sie die Website nicht crawlen können, weil die Website das Crawlen mit Screaming Frog blockiert.
7/ Custom Search and Extraction
CUSTOM SEARCH
Wenn Sie eine spezifische Analyse durchführen möchten, indem Sie Seiten mit bestimmten Elementen in ihrem HTML-Code hervorheben, werden Sie die benutzerdefinierte Suche lieben.
Anwendungsbeispiel:
Sie möchten alle Seiten hervorheben, die Ihren Google Analytics-UA-Code enthalten. Es könnte schlau sein, eine Screaming-Suche durchzuführen, indem Sie Ihren UA-Code in das Suchfenster eingeben. Dies könnte Ihnen zum Beispiel dabei helfen, herauszufinden, ob einige Ihrer Seiten den Analytics-Code nicht installiert haben.
Sie haben einen Blog zum Thema “Geburt” gestartet und möchten sehen, auf welchen Seiten das Wort “box bébé” vorkommt, damit Sie diese Seiten optimieren können? Das ist möglich. Das Einzige, was Sie tun müssen, ist, in Ihr benutzerdefiniertes Suchfeld einzugeben: “box bébé”.
In Ihrer benutzerdefinierten Suche bei Screaming Frog sehen Sie folgendes:
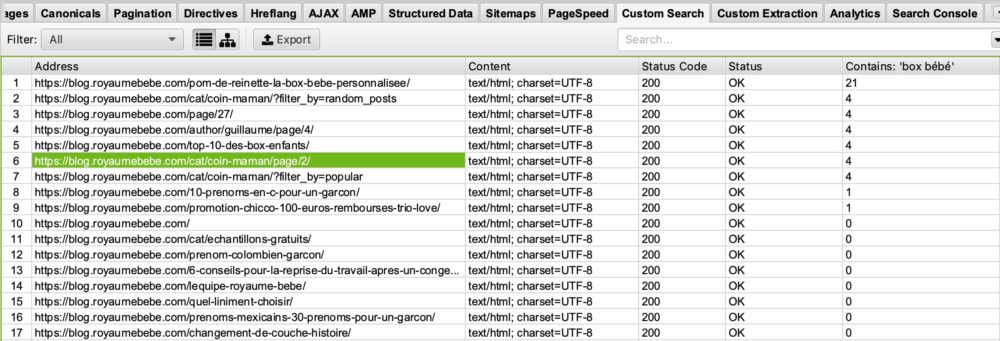
Wenn Sie in der rechten Spalte “Contains: box bébé” nachsehen, sehen Sie, dass Screaming Frog uns die Seiten aufgelistet hat, die das Wort “box bébé” enthalten. Sie können sich sicher vorstellen, wozu Ihnen das später bei Ihren SEO-Optimierungen dienen kann 🙂 .
EXTRACTION
Screaming Frog kann Ihnen mit seiner Extraktionsfunktion auch ermöglichen, bestimmte Daten für Ihre weiteren Analysen zu nutzen. In der Agentur verwenden wir dieses Tool daher immer häufiger für spezielle Analysen.
Um diese Daten abzugreifen, müssen Sie Ihren Extraktor konfigurieren, indem Sie ihm über einen Xpath, einen CSSpath oder einen Regex mitteilen, was er abrufen soll.
Alle Informationen für diese Konfiguration finden Sie in diesem Artikel.
Anwendungsbeispiel:
Möchten Sie das Veröffentlichungsdatum eines Artikels herausfinden und dann entscheiden, bestimmte Artikel zu bereinigen oder neu zu optimieren? Diese Funktion ermöglicht es Ihnen, diese Informationen aus der Ergebnisliste Ihres Screaming Frog zu extrahieren und dann z.B. nach Excel zu exportieren. Großartig, nicht wahr?
Möchten Sie die Liste der Produkte Ihrer Konkurrenten exportieren? Auch hier können Sie Ihren Extraktor einfach so konfigurieren, dass er diese Informationen abruft und dann mit diesen Daten in Excel spielen.
Die Möglichkeiten für den Einsatz dieses Extraktionstools sind grenzenlos. Es liegt an Ihnen, kreativ zu sein und es perfekt zu beherrschen.
8/ API Access
In diesem Fenster können Sie Daten von anderen Tools abrufen, indem Sie Ihren API-Zugang konfigurieren. So können Sie beispielsweise Ihre Daten aus Google Analytics, Google Search Console, Majestic SEO oder Ahrefs einfach in Ihre Informationstabellen für jede URL hochladen. Das bedeutet, dass Ihre Analysen und Audits um ein Vielfaches leistungsfähiger werden.
Der einzige kleine Nachteil: Achten Sie auf Ihre API-Guthaben in den verschiedenen Tools. Das kann sehr schnell aufgebraucht sein.
9/ Authentication
Einige Websites erfordern ein Login und ein Passwort, um auf alle Inhalte zuzugreifen. Screaming Frog ermöglicht es Ihnen, die verschiedenen Zugangsmöglichkeiten über Passwort und Login zu verwalten.
BASIC CASE OF AUTHENTICATION
In den meisten Fällen werden Sie nichts konfigurieren müssen, da Screaming Frog Sie standardmäßig nach einem Login und Passwort fragt, wenn er auf ein Authentifizierungsfenster stößt, um den Crawl durchzuführen.
Dies ist das Fenster, das Sie sehen sollten:
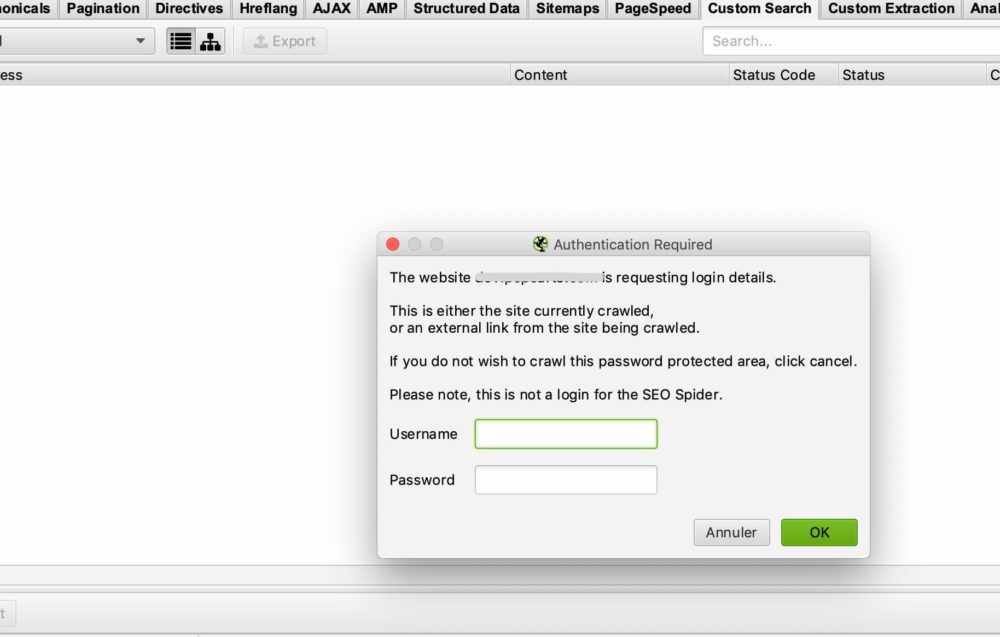
Alles, was Sie tun müssen, ist Ihren Benutzernamen und Ihr Passwort einzugeben und Screaming Frog kann mit dem Crawlen beginnen.
In einigen Fällen kann es eine Blockade durch die Robots.txt geben. In diesem Fall sollten Sie zu Punkt 2/ zurückgehen, um die Robots.txt-Datei zu ignorieren.
CASE OF AN INTERNAL FORM ON THE SITE
Wenn es sich um ein internes Formular auf der Website handelt, können Sie einfach Ihre Zugangsdaten in den formularbasierten Teil der Authentifizierung eingeben und dann dem Crawler den Zugriff auf die Seiten erlauben, die Sie analysieren möchten.
10/ System :
STORAGE
Diese Funktion ist auch dann wichtig, wenn Sie Websites mit mehr als 500 000 URLs crawlen müssen.
In diesem Fenster haben Sie zwei Optionen: Arbeitsspeicher (Memory) und Datenbankspeicher (Storage).
Standardmäßig verwendet Screaming Frog den Arbeitsspeicher, was der Nutzung des RAMs Ihres Computers zum Crawlen der Website gleichkommt. Dies funktioniert sehr gut für Websites, die nicht zu groß sind. Bei Websites mit mehr als 500.000 URLs werden Sie jedoch schnell an die Grenzen stoßen. Ihr Rechner wird unter Umständen erheblich langsamer, und das Crawling kann sehr lange dauern. Vertrauen Sie unserer Erfahrung.
Andernfalls empfehlen wir den Wechsel zur Datenbankspeicherung, insbesondere wenn Sie ein SSD-Laufwerk haben. Ein weiterer Vorteil des Datenbankspeichers ist, dass Ihre Crawls gespeichert und leicht von Ihrer Screaming-Frog-Schnittstelle abgerufen werden können. Selbst wenn das Crawlen unterbrochen wurde, können Sie es wieder aufnehmen. Dies kann Ihnen in manchen Fällen viele Stunden Crawling ersparen.
MEMORY
Hier legen Sie fest, wie viel Arbeitsspeicher Screaming Frog für seine Arbeit verwenden kann. Je mehr Speicher Sie verwenden, desto mehr ist Screaming Frog in der Lage, eine große Anzahl von URLs zu crawlen. Vor allem, wenn er auf Arbeitsspeicher eingestellt ist.
11/ Die Art des Crawlens (Mode) :
SPIDER
Dieser Modus ist die Grundkonfiguration von Screaming Frog. Sobald Sie Ihre URL eingeben, wird Screaming Frog den Links auf Ihrer Website folgen und die gesamte Website crawlen.
LIST
Dieser Modus ist wirklich nützlich, weil er es Ihnen erlaubt, Screaming Frog anzuweisen, eine bestimmte Liste von URLs zu durchsuchen.
Wenn Sie zum Beispiel den Status einer Liste von URLs überprüfen wollen, können Sie einfach eine Datei hochladen oder Ihre Liste von URLs manuell kopieren und einfügen.
SERP
In diesem Modus findet kein Crawling statt. Sie können eine Datei mit z. B. Ihren Titeln und Meta-Beschreibungen hochladen, um zu sehen, wie diese in Bezug auf SEO aussehen würden. So können Sie zum Beispiel die Länge Ihrer Titel und Meta-Beschreibung überprüfen, nachdem Sie Anpassungen in Excel vorgenommen haben.
Analysieren Sie Ihre Crawl-Daten
Die Screaming Frog Schnittstelle:
Bevor Sie sich mit der Analyse der von Screaming Frog bereitgestellten Daten befassen, ist es wichtig zu verstehen, wie die Schnittstelle aufgebaut ist.
Normalerweise sollten Sie folgendes sehen:
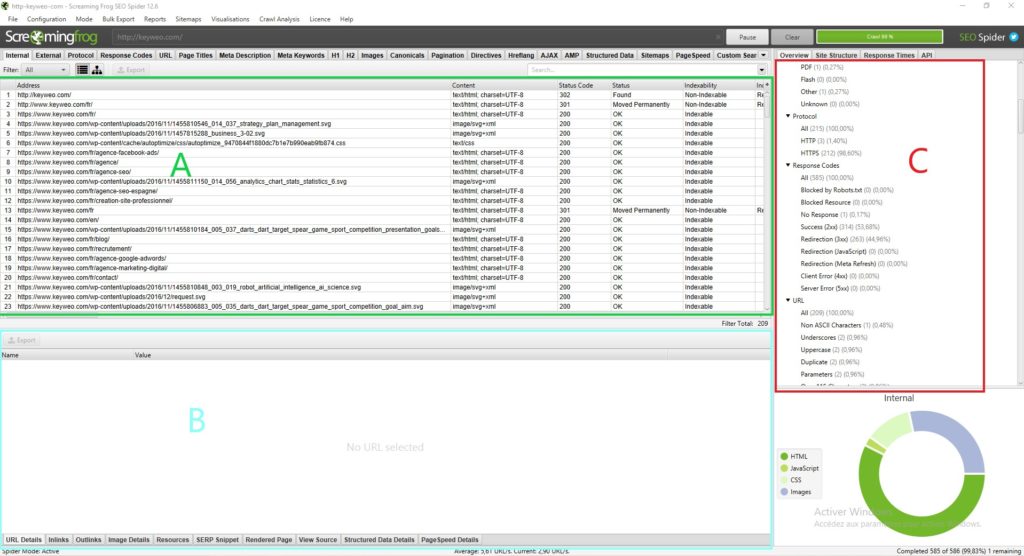
Jeder Abschnitt hat seinen Nutzen und ermöglicht es Ihnen, sich nicht in der Fülle der verfügbaren Daten zu verlieren:
Abschnitt A (in grün): Dieser Abschnitt entspricht der Liste der gecrawlten Seiten mit spezifischen SEO-Angaben für jede Zeile. Im Allgemeinen finden Sie hier die Liste Ihrer Seiten und die spezifischen Informationen zu jeder Seite, wie den Statuscode, die Indexierbarkeit der Seite und die Anzahl der Wörter… Diese Ansicht ändert sich je nachdem, was Sie in Abschnitt C auswählen.
Abschnitt B (in blau): Hier erhalten Sie eine detailliertere Ansicht jeder Ressource, die Sie analysieren, indem Sie sie anklicken. Sie können sich zum Beispiel einen Überblick über die Links, Bilder und andere Informationen auf einer Seite verschaffen, was sehr nützlich sein kann.
Abschnitt C (in rot): Dieser Abschnitt ist wichtig, wenn Sie Ihre Analyse durchführen, da Sie hier sehen können, was optimiert werden kann und Screaming Frog Ihnen auch einige Hilfen gibt, um Ihre Analyse zu erleichtern. Beispiel: Metadaten-Skript fehlt, mehrere H1…
Um Ihren Weg durch die Analyse Ihrer Daten zu erleichtern, empfehlen wir Ihnen, zu dem Abschnitt C zu gehen.
Overview (Abschnitt C):
1/ Summary:
In diesem Abschnitt erhalten Sie einen Gesamtüberblick über die Website, einschließlich der Anzahl der URLs der Website (Bilder, HTML…), der Anzahl der externen und internen URLs, die durch die Robots.txt blockiert werden, der Anzahl der URLs, die der Crawler finden konnte (intern und extern).
So erhalten Sie wertvolle Informationen über die Website auf einen Blick.
2/ Internal
In diesem Abschnitt finden Sie alle internen URLs Ihrer Website.
HTML
Es ist in der Regel sehr interessant, sich die Anzahl der HTML-URLs anzusehen. Sie können zum Beispiel die Anzahl der URLs mit der Anzahl der Seiten vergleichen, die bei Google mit dem Befehl site indexiert sind: Dies kann Ihnen sehr wertvolle Informationen liefern, wenn zum Beispiel viele Seiten bei Google nicht indiziert sind.
Wenn Sie auf HTML klicken, werden Sie sehen, dass Ihre linke Seite eine Menge wichtiger Informationen enthält, die Sie analysieren können, wie z.B.:
=> Statuscode der Seite
=> Indexierbarkeit
=> Informationen zum Titel (Inhalt, Größe)
=> Informationen zur Meta-Beschreibung (Inhalt, Größe)
=> Meta-Keyword: nicht unbedingt sehr nützlich, es sei denn, sie werden von der betreffenden Website noch verwendet. Zum Beispiel könnten Sie diese Tags bereinigen
=> H1 (Der Inhalt, die Größe und das Vorhandensein einer zweiten H1 und deren Größe)
=> H2 (Der Inhalt, die Größe, das Vorhandensein einer zweiten H2 und deren Größe)
=> Meta-Roboter
=> X Robots Tag
=> Meta Refresh
=> Das Vorhandensein eines canonical
=> Das Vorhandensein eines rel next oder rel prev Tags
=> Die Größe der Seite
=> Die Anzahl der Wörter auf der Seite
=> Das Textverhältnis: Verhältnis von Text zu Code
=> Die Crawl-Tiefe: Die Tiefe der betreffenden Seite auf der Website. Die Startseite befindet sich auf Ebene 0, wenn Sie mit dem Crawlen dieser Seite beginnen. Eine Seite, die 1 Klick von der Startseite entfernt ist, hat die Tiefe 1 und so weiter. Im Allgemeinen ist es interessant, die Tiefe auf Ihrer Website zu verringern
=> Inlinks / Unique Links: Anzahl der internen Links, die auf die betreffende Seite zeigen
=> Outlinks / Unique outlinks: Anzahl der ausgehenden Links von dieser Seite
=> Response time: Antwortzeit der Seite
=> Redirect URL: Seite, auf die die Seite umgeleitet wird
Sie können alle diese Elemente auch finden, indem Sie die verschiedenen Elemente in der rechten Spalte durchgehen.
Wenn Sie die API der Search Console, Google Analytics, Ahrefs… anschließen, stehen Ihnen noch weitere Spalten zur Verfügung, die für eine Analyse sehr interessant sind.
JAVASCRIPT, IMAGES, CSS, PDF…
Wenn Sie auf jeden Abschnitt klicken, erhalten Sie interessante Informationen über jede Art von Ressource auf Ihrer Website.
3/ External
Der externe Teil entspricht allen URLs, die außerhalb Ihrer Website verweisen. Hier finden Sie zum Beispiel alle externen Links, die Sie erstellen.
Es kann interessant sein, die ausgehenden URLs Ihrer Website zu analysieren und ihren Status zu sehen. Wenn Sie 404 Links haben, ist es ratsam, diese zu korrigieren oder zu entfernen, um zu vermeiden, dass Sie auf fehlerhafte Seiten verlinken.
4/ Protocol:
In diesem Abschnitt können Sie HTTP- und HTTPS-URLs identifizieren.
Wenn Sie HTTP-URLs oder Duplikate von HTTP- und HTTPS-Seiten haben, wäre es hilfreich, die Umleitung Ihrer HTTP-Seiten auf ihre HTTPS-Version zu verwalten.
Ein weiterer Punkt ist, dass Sie bei HTTP-URLs, die auf andere Websites verweisen, prüfen sollten, ob die HTTPS-Version dieser Websites nicht existiert und die Links ersetzen.
5/ Response Codes:
Der Abschnitt Response Codes gruppiert Ihre Seiten nach Code-Typ.
=> No response: Dies betrifft im Allgemeinen Seiten, die der Screaming Frog nicht crawlen konnte
=> Success: Alle Ihre Seiten sollten hier den Status 200 haben, d.h. sie sind erreichbar
=> Redirection: Dieser Abschnitt sollte alle Seiten mit Status 300 (301, 302, 307…) enthalten. Es könnte interessant sein, zu sehen, wie man diese Zahl reduzieren kann, um Google direkt auf Seiten mit Status 200 zu schicken
=> Client Error: Hier sind alle Seiten im Fehlerzustand mit einem Status von, zum Beispiel, 404. Es wird wichtig sein, die Ursache zu untersuchen und einen Redirect durchzuführen.
=> Server Error: Alle Seiten mit einem Serverfehler
6/ URL:
In diesem Bereich finden Sie die Liste Ihrer URLs und die damit verbundenen möglichen Probleme oder Verbesserungen.
Sie können z.B. sehen, ob Ihre URLs großgeschrieben sind oder ob es sich um doppelte URLs handelt.
7/ Page Titles:
Hier erhalten Sie viele Informationen über Ihre Titel und können sie optimieren, um sie SEO-freundlicher zu machen.
Hier sind die Informationen, die Sie finden können:
=> Missing: Dies bezieht sich auf Ihre Seiten, die keinen Titel haben. Sie sollten sie also nach Möglichkeit hinzufügen
=> Duplicate: Hier finden Sie alle duplizierten Titel Ihrer Website. Ideal ist es, diese zu vermeiden. Es liegt an Ihnen, zu sehen, wie Sie sie optimieren können, um Duplikate zu vermeiden
=> Mehr als 60 Zeichen: Ab einer bestimmten Anzahl von Zeichen werden Ihre Titel in den Google-Ergebnissen abgeschnitten. Achten Sie darauf, dass sie etwa 60 Zeichen lang sind, um Probleme zu vermeiden.
=> Unter 30 Zeichen: Hier finden Sie die Titel, die Sie in Bezug auf die Größe optimieren können. Durch Hinzufügen einiger strategischer Wörter, können Sie sie optimieren, um die näher an 60 Zeichen zu kommen
=> Mehr als 545 Pixel / weniger als 200 Pixel: Wie die vorherigen Elemente gibt dies die Länge Ihrer Titel an, aber diesmal in Pixeln. Der Unterschied ist, dass Sie Ihre Titel optimieren können, indem Sie Buchstaben mit mehr oder weniger Pixeln verwenden, um den Platz zu maximieren.
=> Wie H1: Dies bedeutet, dass Ihr Titel mit Ihrer H1 identisch ist.
=> Mehrere: Wenn Sie Seiten mit mehreren Titeln haben, können Sie hier das Problem identifizieren und sehen, welche Seiten korrigiert werden müssen
8/ Meta Description:
Nach dem gleichen Muster wie bei den Titeln finden Sie in diesem Abschnitt zahlreiche Anweisungen zur Optimierung Ihrer Meta-Beschreibung, die sich auf ihre Größe, ihr Vorhandensein oder die Tatsache beziehen, dass sie doppelt vorhanden sind.
9/ Meta Keywords:
Es ist nicht unbedingt sinnvoll, sie zu berücksichtigen, es sei denn, die Seiten scheinen sehr viele davon zu haben.
Es liegt an Ihnen.
10/ H1 / H2:
In diesen Abschnitten können Sie sehen, ob Ihre Hn-Tags optimiert werden müssen.
Wenn Sie z. B. mehrere H1-Tags auf einer Seite haben, könnte es interessant sein, nur einen beizubehalten. Oder wenn Sie doppelte H1-Tags auf Ihren Seiten haben, könnten Sie diese überarbeiten.
11/ Images:
Durch eine allgemeine Analyse dieses Abschnitts können Sie Optimierungen für Ihre Bilder finden, z. B. die Überarbeitung von Bildern mit mehr als 100 KB oder das Hinzufügen von Alt-Symbolen bei Bildern, die keine haben.
12/ Canonical:
Ein kanonisches Tag wird verwendet, um Google mitzuteilen, dass es zu einer bestimmten Seite gehen soll, weil es die Originalseite ist. Ein solches kanonisches Tag gibt Google eine Idee, welche Seite indiziert werden muss, wenn es mehrere Seiten mit ähnlichem Inhalt gibt.
13/ Pagination:
Hier finden Sie alle Informationen über die Paginierung auf Ihrer Website, damit Sie sie besser verwalten können.
14/ Directives:
Der Richtlinien-Teil zeigt die Informationen, die im Meta-Robots-Tag und X-Robots-Tag enthalten sind. Sie können die Seiten in No-Index, No-Follow, etc. sehen.
15/ Hreflang:
Bei der Prüfung einer mehrsprachigen Website ist es sehr wichtig zu prüfen, ob die Website über hreflang-Tags verfügt, um Google zu helfen, die auf der Website verwendete Sprache zu verstehen, auch wenn davon ausgegangen werden kann, dass Google selbst zunehmend in der Lage ist, sie zu verstehen.
16/ AMP:
Hier landen Ihre AMP-Seiten und Sie können die damit verbundenen SEO-Probleme erkennen.
17/ Structured data:
Um Informationen in diesem Abschnitt zu erhalten, müssen Sie in Ihrer Spider-Konfiguration die spezifischen Elemente für strukturierte Daten aktivieren: JSON-LD, Microdata und RDFa.
Sie erhalten viele Informationen, um Ihre Implementierung von strukturierten Daten auf der Website zu optimieren.
18/ Sitemaps:
In diesem Teil können Sie die Unterschiede zwischen dem, was Sie auf Ihrer Website und in Ihrer Sitemap haben, erkennen.
Dies ist zum Beispiel eine gute Möglichkeit, Orphan Pages zu identifizieren.
Um Daten in diesem Bereich zu erhalten, müssen Sie in der Crawler-Konfiguration auch die Möglichkeit aktivieren, Ihre Sitemap zu crawlen. Um die Sache zu vereinfachen, fügen Sie den Link zu Ihrer Sitemap direkt in der Konfiguration hinzu.
19/ Pagespeed:
Mit der Page Speed Insight API können Sie die Geschwindigkeitsprobleme Ihrer Seiten leicht identifizieren und durch die Analyse der Daten auf dieser Registerkarte beheben.
20/ Custom Search und Extraction:
Wenn Sie Elemente scrapen oder den Code einer Seite gezielt durchsuchen wollen, finden Sie hier die Daten.
21/ Analytics und Search Console:
Sie können eine Menge nützlicher Informationen in diesen Tabs finden, indem Sie Screaming Frog auch mit der Analytics und Search Console API verbinden.
Zum Beispiel können Sie auch die Orphan Pages finden, die in Ihren Tools vorhanden sind, aber nicht im Crawl oder die Seiten mit einer Absprungrate von mehr als 70%.
22/ Link Metrics:
Verbinden Sie Screaming Frog mit Ahrefs und Majestic APIs und erhalten Sie Informationen über das Netlinking Ihrer Seiten (Beispiel: Trustflow, Citation Flow…)
Zusätzliche Funktionen von Screaming Frog
Analysieren Sie die Tiefe einer Website (Site Structure):
Wenn Sie die Tiefe Ihrer Site sehen wollen, kann es sehr interessant sein, die Registerkarte Site-Struktur aufzurufen.
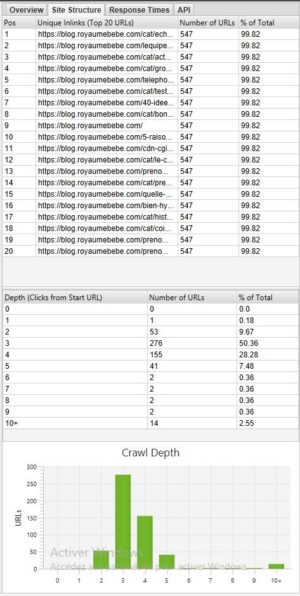
Im Allgemeinen ist es besser, eine Website zu haben, bei der die meisten Seiten mit 3 – 4 Klicks erreichbar sind. In unserem obigen Beispiel sollten wir die Tiefe optimieren, denn es gibt Seiten, die mit mehr als 10 Klicks erreichbar sind.
Visualisierung Ihrer Website:
Sobald Ihr Crawl abgeschlossen ist, kann es interessant sein, unter Visualizations > Forced Directed Crawl Diagram einen Überblick über Ihre Website in Form eines Diagramms zu erhalten.
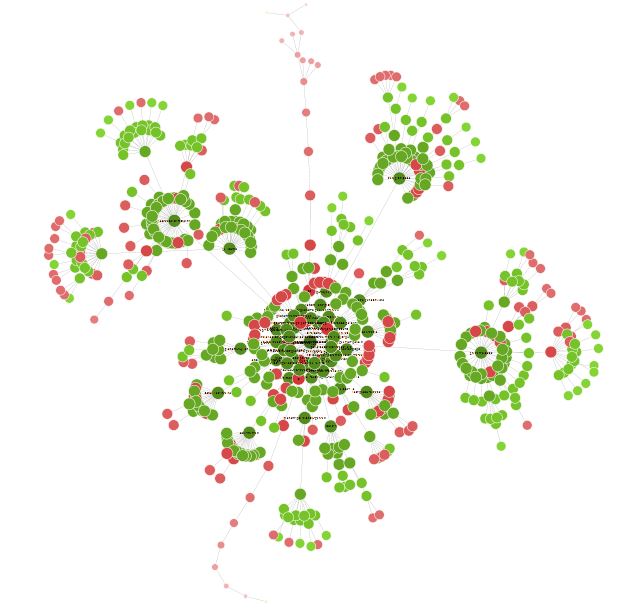
Alle kleinen roten Punkte können analysiert werden, um zu verstehen, ob es ein Problem gibt oder nicht.
Sie können einige Zeit mit dieser Visualisierung verbringen, um viele interessante Optimierungswege zu finden.
Fazit zu Screaming Frog
Screaming Frog ist daher ein unverzichtbares Werkzeug für jede gute SEO. Mit dem Tool können Sie viele Dinge tun, von der technischen SEO-Analyse bis zum Site Scraping.